
Georg Lukas, 2025-05-05 18:40
This is a follow-up to the Samsung NX mini (M7MU) firmware reverse-engineering series. This part is about the proprietary LZSS compression used for the code sections in the firmware of Samsung NX mini, NX3000/NX3300 and Galaxy K Zoom. The post is documenting the step-by-step discovery process, in order to show how an unknown compression algorithm can be analyzed. The discovery process was supported by Igor Skochinsky and Tedd Sterr, and by writing the ideas out on encode.su.
The initial goal was to understand just enough of the algorithm to extract and disassemble the ARM code for (de)compression. Unfortunately, this turned out as impossible when, after the algorithm was already mostly demystified, Igor identified it as Fujitsu's RELC (Rapid Embedded Lossless data Compression), an embedded hardware IP block on their ARM SoCs.
The TL;DR results of this research can be found in the project wiki: M7MU Compression.
Layer 1: the .bin file
Part 1 identified the .bin files that
can be analyzed, derived the container format and created an
extraction tool
for the section files within a firmware container.
The analysis in this post is based on the chunk-05.bin section file
extracted from the NX mini firmware version 1.10:
5301868 Apr 8 16:57 chunk-01.bin
1726853 Apr 8 16:57 chunk-02.bin
16 Apr 8 16:57 chunk-03.bin
400660 Apr 8 16:57 chunk-04.bin
4098518 Apr 8 16:57 chunk-05.bin
16 Apr 8 16:57 chunk-06.bin
16 Apr 8 16:57 chunk-07.bin
Layer 2: the sections
The seven section files are between 16 bytes and 5.2MB, the larger ones
definitively contain compressed data (strings output yields incomplete /
split results, especially on longer strings like copyright notices):
<chunk-01.bin>
Copyright (C) ^A^T^@^F, Arcsoft Inc<88>
<chunk-02.bin>
Copyright^@^@ (c) 2000-2010 b^@<95>y FotoNa^QT. ^@<87> ^B's^Qñ^A1erved.
<chunk-05.bin>
Copyright (c) 2<80>^@^@5-2011, Jouni Ma^@^@linen <*@**.**>
^@^@and contributors^@^B^@This program ^@^Kf^@^@ree software. Yo!
u ^@q dis^C4e it^AF/^@<9c>m^D^@odify^@^Q
under theA^@ P+ms of^B^MGNU Gene^A^@ral Pub^@<bc> License^D^E versPy 2.
The wpa_supplicant license inside chunk-05.bin indicates that it's the
network / browser / image upload code, which I need to understand in order to
fix
NX mini support in my Samsung API reimplementation.
Given how compression algorithms replace repeating patterns from the input with references, we can expect the data at the beginning of a compressed file to have fewer references and thus be easier to understand.
Ideally, we need to find some compressed data for which we know the precise uncompressed plain-text, in order to correlate which parts of the stream are literals and which parts are references.
The sections 1, 2, 4 and 5 all contain debug strings close to their respective beginning. This indicates that each section file is compressed individually, an important preliminary insight. However, some of the debug strings have spelling issues, and searching for them on the internet doesn't give us any plain-text reference:
-- Myri^@^@ad --makememlog.^@^@txt is not exist ^@
^@^@^AOpDebugMemIni ^@t ^@+roy alloc OK
^@^H^@´¢éAè@0A--[^CT] H^@^@EAP_ALLOC_TOTAL=^A^@%u
LZSS compression primer
The pattern visible in long strings, where the string is interrupted by two zero bytes after 16 characters, was quickly identified as a variant of LZSS by Igor. I hadn't encountered that before, and still had traumatic memories from variable bit-length Huffman encodings which I deemed impossible to analyze.
Luckily, LZSS operates on whole bytes and is rather straightforward to understand and to implement. The "Sliding window compression" section of Unpacking HP Firmware Updates does a decent job of explaining it on a practical example.
Each block in the compressed stream begins with a bitmask, identifying which of the following bytes are literals that need to be directly inserted into the output stream, and which ones are tokens, representing a lookup into the previously decompressed data. To limit the required memory use, the decompressed data is limited to a fixed size window of some kilobytes. Each token is a tuple of offset (how far back the referenced data is from the end of the window) and length (how many bytes to copy).
The number of bits used to encode the bitmask, the offset, and the length in the token vary with different implementations. More bits for the offset allow for a larger window with more reference data to choose from, more bits for the length allow to copy longer segments with a single token reference.
In the linked example, an 8-bit bitmask is used for each block, and the 16-bit
token is split into 12 bits for the offset, implying a 2^12 = 4096 byte
window, and 4 bits for length, allowing to reference up to 15+3=18 bytes.
As can be seen, the efficiency gains from only using two bytes are limited, so in some LZSS variants, a variable-length encoding is used in the token to allow even longer references.
Layer 4: the blocks
The best way to understand the parameters of the LZSS variant is to compare the compressed stream with the expected plain-text stream byte for byte. For this, we still need a good known plain-text reference. In fact, the garbled wpa_supplicant license that I found back in 2023 is excellent for that, as it's mostly static text from the wpa_supplicant.c source code:
"wpa_supplicant v" VERSION_STR="0.8.x" "\n"
"Copyright (c) 2003-2011, Jouni Malinen <j@w1.fi> and contributors"
"This program is free software. You can distribute it and/or modify it\n"
"under the terms of the GNU General Public License version 2.\n"
"\n"
"Alternatively, this software may be distributed under the terms of the\n"
"BSD license. See README and COPYING for more details.\n"
Looking at the file history in git, there are only two moving parts: the
VERSION_STR that encodes the respective
(pre-)release,
and the second year of the copyright. The NX mini firmware therefore contains
a "0.8.x" version from between
February 2011
and
January 2012.
We should look a few bytes ahead of the actual copyright string
"wpa_suppl..." (offset 0x003d1acb):
003d1ab0: 4749 4e00 6172 4852 334b 5933 0000 2066 GIN.arHR3KY3.. f
003d1ac0: 6f72 2054 6872 6561 6458 0077 7061 0200 or ThreadX.wpa..
003d1ad0: 5f73 7570 706c 48b2 6e74 2076 302e 382e _supplH.nt v0.8.
003d1ae0: 7800 000a 436f 7079 7269 6768 7420 2863 x...Copyright (c
003d1af0: 2920 3280 0000 352d 3230 3131 2c20 4a6f ) 2...5-2011, Jo
003d1b00: 756e 6920 4d61 0000 6c69 6e65 6e20 3c6a uni Ma..linen <j
003d1b10: 4077 312e 6669 3e20 0000 616e 6420 636f @w1.fi> ..and co
003d1b20: 6e74 7269 6275 746f 7273 0002 0054 6869 ntributors...Thi
003d1b30: 7320 7072 6f67 7261 6d20 000b 6600 0072 s program ..f..r
003d1b40: 6565 2073 6f66 7477 6172 652e 2059 6f21 ee software. Yo!
003d1b50: 0a75 2000 7120 6469 7303 3465 2069 7401 .u .q dis.4e it.
003d1b60: 462f 009c 6d04 006f 6469 6679 0011 0a75 F/..m..odify...u
003d1b70: 6e64 6572 2074 6865 4100 2050 2b6d 7320 nder theA. P+ms
003d1b80: 6f66 020d 474e 5520 4765 6e65 0100 7261 of..GNU Gene..ra
003d1b90: 6c20 5075 6200 bc20 4c69 6365 6e73 6504 l Pub.. License.
003d1ba0: 0520 7665 7273 5079 2032 2e0a 0a41 6c00 . versPy 2...Al.
003d1bb0: 366e 5089 0701 7665 6c79 2c00 3a00 8805 6nP...vely,.:...
003d1bc0: 8320 6d61 7920 6265 0781 0120 4664 2007 . may be... Fd .
003d1bd0: 6e0c 0a42 5344 206c 035f 2e20 5300 c730 n..BSD l._. S..0
003d1be0: fb44 2190 4d45 02f4 434f 5059 3013 0a53 .D!.ME..COPY0..S
003d1bf0: 6d6f 0057 6465 7461 044b 696c 732e 0a0f mo.Wdeta.Kils...
...
Assuming that the plain-text bytes in the compressed block are literals and the
other bytes are control bytes, we can do a first attempt at matching and
understanding the blocks and their bitmasks as follows, starting at what looks
like the beginning of a compression block at offset 0x3d1abc:
003d1abc: 00 00 = 0000.0000.0000.0000b // offset: hex and binary bitmask
003d1abe: literal 16 " for ThreadX\0wpa"
In the manually parsed input, "literal N" means there are N bytes matching the known license plain-text, and "insert N" means there are no literals matching the expected plain-text, and we need to insert N bytes from the lookup window.
The first block is straight-forward. 16 zero bits followed by 16 literal bytes
of NUL-terminated ASCII text. We can conclude that the bitmask has 16 bits,
and that a 0 bit stands for "literal".
The second block is slightly more complicated:
003d1ace: 02 00 = 0000.0010.0000.0000b
003d1ad0: literal 6 "_suppl"
003d1ad6: 48 b2 insert 3 "ica" (location yet unknown)
003d1ad8: literal 9 "nt v0.8.x"
The bitmask has six 0 bits, then a single 1 bit at position 7, then nine
more 0s, counting from most to least significant bit. There are two apparent
literal strings of 6 and 9 bytes, with two unknown bytes 0x48 0xb2 between
them that correspond to the three missing letters "ica". We can conclude that
the bitmask is big-endian, processed from MSB to LSB, the 1 in the bitmask
corresponds to the position of the token, and the token is encoded with two
bytes, which is typical for many LZSS variants.
003d1ae1: 00 00 = 0000.0000.0000.0000b
003d1ae3: literal 16 "\nCopyright (c) 2"
Another straight forward all literal block.
003d1af3: 80 00 = 1000.0000.0000.0000b
003d1af5: 00 35 insert 3 "003"
003d1af7: literal 15 "-2011, Jouni Ma"
The above block bitmask has the MSB set, meaning that it's directly followed
by a token. The "5" in the compressed stream ("5-2011") is a red herring and
not actually a part of the year. The copyright string reads "2003-2011" in all
revisions, it never had "2005" as the first year. Therefore, it must be part
of a token (0x00 0x35).
003d1b06: 00 00; literal 16 "linen <j@w1.fi> "
003d1b18: 00 00; literal 16 "and contributors"
Now this is getting boring, right?
003d1b2a: 00 02 = 0000.0000.0000.0010b
003d1b2c: literal 14 "\0 This program "
003d1b3a: 00 0b insert 3 "is "
003d1b3c: literal 1 "f"
Without looking at the token encoding, we now have identified the block structure and the bitmask format with a high confidence.
Decoding just the literals, and replacing tokens with three-byte "*" placeholders, we get the following output:
00000000: 2066 6f72 2054 6872 6561 6458 0077 7061 for ThreadX.wpa
00000010: 5f73 7570 706c **** **6e 7420 7630 2e38 _suppl***nt v0.8
00000020: 2e78 0a43 6f70 7972 6967 6874 2028 6329 .x.Copyright (c)
00000030: 2032 **** **2d 3230 3131 2c20 4a6f 756e 2***-2011, Joun
00000040: 6920 4d61 6c69 6e65 6e20 3c6a 4077 312e i Malinen <j@w1.
00000050: 6669 3e20 616e 6420 636f 6e74 7269 6275 fi> and contribu
00000060: 746f 7273 0054 6869 7320 7072 6f67 7261 tors.This progra
00000070: 6d20 **** **66 7265 6520 736f 6674 7761 m ***free softwa
Layer 5: the tokens
Now we need to understand how the tokens are encoded, in order to implement
the window lookups. The last block is actually a great example to work from:
the token value is 00 0b and we need to insert the 3 characters "is " (the
third character is a whitespace). 0x0b == 11 and the referenced string is
actually contained in the previously inserted literal, beginning 11 characters
from the end:
003d1b2c: literal 14 "\0 This program "
☝️☝️8←6←4←2←0
003d1b3a: 00 0b insert 3 "is " (offset -11)
003d1b3c: literal 1 "f"
Two-byte tokens are typical for many LZSS variants. To be more efficient than literals, a token must represent at least three bytes of data. Therefore, the minimum reference length is 3, allowing the compressor to subtract 3 when encoding the length value - and requiring to add 3 when decompressing.
From the above token, we can conclude that the offset is probably stored in
the second byte. The minimum reference length is 3, which is encoded as 0x0,
so we need to look at a different example to learn more about the length
encoding. All the tokens we decoded so far had a length of 3, so we need to
move forward to the next two blocks:
003d1b3d: 00 00 = 0000.0000.0000.0000b
003d1b3f: literal 16 "ree software. Yo"
003d1b4f: 21 0a = 0010.0001.0000.1010b
003d1b51: literal 2 "u "
003d1b53: 00 71 insert 3 "can"
003d1b55: literal 4 " dis"
003d1b59: 03 34 insert 6 "tribut" (offset -52?)
003d1b5b: literal 4 "e it"
003d1b5f: 01 46 insert 4 " and" (offset -70?)
003d1b61: literal 1 "/"
003d1b62: 00 9c insert 3 "or "
003d1b64: literal 1 "m"
The last block gives us two tokens with lengths of 6 (to be encoded as 0x3)
and 4 (0x1). These values match the first byte of the respective
token. However, using the whole byte for the length would limit the window
size to meager 256 bytes, an improbable trade-off. We should look for a token
with a known short length and as many bits in the first byte set as possible.
We had such a token in the beginning actually:
003d1ad6: 48 b2 insert 3 "ica" (location yet unknown)
We already know that the length is encoded in the lower bits of the first
byte, with length=3 encoded as 0x0. In 0x48 = 0100.1000b, we only get
three zero bits at the bottom of the byte, limiting the length to 7+3 = 10,
which is another improbable trade-off.
That also implies that the upper five bits, together with the second byte,
form a 13-bit offset into a 2^13=8192 byte window. By removing the length
bits from the first byte, 0x48b2 becomes the offset 0x09b2 = 2482.
hi, lo = f.read(2)
count = 3 + (hi & 0x07)
offset = ((hi >> 3) << 8) + lo
We apply the window lookup algorithm to our compressed stream, and arrive at the following uncompressed plain-text:
00000000: 2066 6f72 2054 6872 6561 6458 0077 7061 for ThreadX.wpa
00000010: 5f73 7570 706c **** **6e 7420 7630 2e38 _suppl***nt v0.8
00000020: 2e78 0a43 6f70 7972 6967 6874 2028 6329 .x.Copyright (c)
00000030: 2032 **** **2d 3230 3131 2c20 4a6f 756e 2***-2011, Joun
00000040: 6920 4d61 6c69 6e65 6e20 3c6a 4077 312e i Malinen <j@w1.
00000050: 6669 3e20 616e 6420 636f 6e74 7269 6275 fi> and contribu
00000060: 746f 7273 0054 6869 7320 7072 6f67 7261 tors.This progra
00000070: 6d20 6973 2066 7265 6520 736f 6674 7761 m is free softwa
00000080: 7265 2e20 596f 7520 **** 6e20 6469 7374 re. You **n dist
00000090: 7269 6275 7465 2069 7420 616e 642f 6f72 ribute it and/or
000000a0: 206d 6f64 6966 7920 6974 0a75 6e64 6572 modify it.under
000000b0: 2074 6865 20** **** 6d73 206f 6620 7468 the ***ms of th
000000c0: 6520 474e 5520 4765 6e65 7261 6c20 5075 e GNU General Pu
000000d0: 626c **** 204c 6963 656e 7365 2076 6572 bl** License ver
000000e0: 73** **** 2032 2e0a 0a41 6c** **** 6e** s*** 2...Al***n.
000000f0: **** 7665 6c79 2c20 7468 6973 2073 6f66 **vely, this sof
00000100: 7477 6172 6520 6d61 7920 6265 2064 6973 tware may be dis
00000110: 7472 6962 7574 4664 2007 6e0c 0a** **** tributFd .n..***
00000120: **** 4420 **** **** **** **5f 2e20 5300 **D *******_. S.
As we started the decompression in the middle of nowhere, the window isn't properly populated, and thus there are still streaks of "*" for missing data.
However, there is also a mismatch between the decompressed and the expected plain-text in the last two lines, which cannot be explained by missing data in the window:
00000110: 7472 6962 7574 4664 2007 6e0c 0a** **** tributFd .n..***
00000120: **** 4420 **** **** **** **5f 2e20 5300 **D *******_. S.
What is happening there? We need to manually look at the last two blocks to see what goes wrong:
003d1bb4: 07 01 = 0000'0111'0000'0001b
003d1bb6: literal 5 "vely,"
003d1bbb: 00 3a insert 3 " th" (offset -58)
003d1bbd: 00 88 insert 3 "is " (offset -136)
003d1bbf: 05 83 insert 8 "software" (offset -131)
003d1bc1: literal 7 " may be"
003d1bc8: 07 81 insert 10 " distribut" (offset -129)
003d1bca: 01 20 = 0000'0001'0010'0000b
003d1bcc: literal 7 "Fd \0x07n\x0c\n"
Quite obviously, the referenced "distribut" at 0x3d1bc8 is correct, but after
it comes garbage. Incidentally, this token is the first instance where the
encoded length is 0x7, the maximum value to fit into our three bits.
Variable length tokens
The lookup window at offset -129 contains "distribute it", and the plain-text that we need to emit is "distributed".
We could insert "distribute" (11 characters instead of 10) from the window,
and we can see a literal "d" in the compressed data at 0x3d1bcd that would
complement "distribute" to get the expected output. Between the token and the
literal we have three bytes: 0x01 0x20 0x46.
What if the first of them is actually a variable-length extension of the token? The maximum lookup of 10 characters noted earlier is not very efficient, but it doesn't make sense to make all tokens longer. Using a variable-length encoding for the lookup length makes sense (the window size is fixed and only ever needs 13 bits).
Given that we need to get from 10 to 11, and the next input byte is 0x01,
let's assume that we can simply add it to the count:
hi, lo = f.read(2)
count = 3 + (hi & 0x07)
offset = ((hi >> 3) << 8) + lo
if count == 10:
# read variable-length count byte
count += f.read(1)[0]
With the change applied, our decoding changes as follows:
...
003d1bc8: 07 81 01 insert 11 " distribut" (offset -129)
003d1bcb: 20 46 = 0010'0000'0100'0110b
003d1bcd: literal 2 "d "
003d1bcf: 07 6e 0c insert 22 "under the terms of the" (offset -110)
003d1bd2: literal 6 "\nBSD l"
003d1bd8: 03 4f insert 6 "icense" (offset -95)
003d1bda: literal 3 ". S"
003d1bdd: 00 c7 insert "ee " (offset -199)
003d1bdf: 30 fb insert "***" (offset -1787)
003d1be1: literal 1 "D"
This actually looks pretty good! We have another three-byte token in the next
block at 0x3d1bcf, with a lookup length of 22 bytes (3 + 0x7 + 0x0c) that
confirms our assumption. The uncompressed output got re-synchronized as well:
00000110: 7472 6962 7574 6564 2075 6e64 6572 2074 tributed under t
00000120: 6865 20** **** 6d73 206f 6620 7468 650a he ***ms of the.
00000130: 4253 4420 6c69 6365 6e73 652e 2053 6565 BSD license. See
00000140: 20** **** 444d 4520 616e 6420 434f 5059 ***DME and COPY
How long is the length? YES!
With the above, the common case is covered. Longer lengths (>265) are rare in the input and hard to find in a hex editor. Now it makes sense to instrument the tooling to deliberately explode on yet unidentified corner cases.
There exist different variable-length encodings. The most-widely-known one is probably UTF-8, but it's rather complex and not well-suited for numbers. The continuation bit encoding in MIDI is a straight-forward and sufficiently efficient one. The trivially blunt approach would be to keep adding bytes until we encounter one that's less than 255.
In the case of MIDI, we need to check for cases of count > 138, in the
latter for count > 265.
if count == 10:
# read variable-length count byte
count += f.read(1)[0]
if count > (10 + 128):
print(f"{f.tell():08x}: BOOM! count > 138!")
count = count - 128 + f.read(1)[0]
Running the code gives us a canary at an offset to manually inspect:
003d2e53: BOOM! count > 138!
003d2e51: ef 18 c0 insert 172 "d\x00ca_cert\x00ca_path\x00cut nt_cert\x00 d\x01"
"vlai_key_us_\x01dd\x00dh_f\x01\x01\x01\x01subjec"
"t_ollch\x00altsubject_ollch\x00ty\x00pass2word\x"
"00ca_2cert\x00ca_path2\x00 d\x01vlai_keyrt\x00 d"
"\x01vlai_key_2us_\x01dd\x00dh_f\x01\x01\x012\x01"
"subject_ol" (offset -7448)
Now this does not look like a very nice place to manually check whether the data is valid. Therefore, it makes sense to run different variants of the decoder on the complete input and to compare and sanity-check the results.
Keeping assertion checks of the assumed stream format allows to play around with different variants, to see how far the decoder can get and to find incorrect reverse-engineering assumptions. This is where the FAFO method should be applied extensively.
Applying the FAFO method (after figuring out the subsection format outlined later in this post) led to the realization that the variable-length length encoding is actually using the brute-force addition approach:
hi, lo = f.read(2)
count = 3 + (hi & 0x07)
offset = ((hi >> 3) << 8) + lo
if count == 10:
more_count = 255
while more_count == 255:
more_count = f.read(1)[0]
count += more_count
Well, surely this can't be too bad, how long is the longest streak of repeating data in the worst case?
Well. chunk-01.bin wins the length contest:
0046c204: literal b'\x00'
0046c205: token 0x0701ffffffffffffffffffffffffffffffffff56: 4431 at -1
<snip>
0046c21d: bitmask 0xc0000
0046c21f: token 0x0701ffffffffffffffffffffffffffffffffffffffffffffffffff \
ffffffffffffffffffffffffffffffffffffffffffffffffffffff \
ffffffffffffffffffffffffffffffffffffffffffffffffffffff \
ffffffffffffffffffffffffffffffffff56: 24576 at -1
0046c282: token 0x0000: 3 at -0
Oof! Samsung is using 97 length extension bytes to encode a lookup length of 24576 bytes. This is still a compression ratio of ~250x, so there is probably no need to worry.
By the way, offset=-1 essentially means "repeat the last byte from the
window this many times". And offset=0 (or rather token=0x0000) is some
special case that we have not encountered yet.
Back to layer 3: the subsections
So far, we started decoding at a known block start position close to the identified plain-text. Now it's time to try decompressing the whole file.
When applying the decompression code right at the beginning of one of the compressed files, it falls apart pretty quickly (triggering an "accessing beyond the populated window" assertion):
$ m7mu-decompress.py -d -O0 chunk-01.bin
00000000 (0): bitmask 0x623f=0110'0010'0011'1111b
literal b'\x00'
token 0x0070=0000'0000'0111'0000b: 3 at -112
IndexError: 00000000: trying to look back 112 bytes in a 1-sized window
$ m7mu-decompress.py -d -O1 chunk-01.bin
00000001 (0): bitmask 0x3f00=0011'1111'0000'0000b
literal b'\x00p'
token 0x477047=0100'0111'0111'0000'0100'0111b: 81 at -2160
IndexError: 00000001: trying to look back 2160 bytes in a 2-sized window
$ m7mu-decompress.py -d -O2 chunk-01.bin
00000002 (0): bitmask 0x0000=0000'0000'0000'0000b
literal b'pGpG\x01F\x81\xea\x81\x00pG8\xb5\xfaH'
00000014 (1): bitmask 0x0000=0000'0000'0000'0000b
literal b'\x00%iF\x05`\xf9H@h\xda\xf5|\xd9\x10\xb1'
00000026 (2): bitmask 0x0000=0000'0000'0000'0000b
literal b'\xf7\xa0\xe7\xf5\x11\xdc\x00\x98\xb0\xb1\xf4L\x0c4%`'
<snip very long output>
This leads to the assumption that the first two bytes, 0x62 0x3f for
chunk-05.bin, are actually not valid compression data, but a header or count
or size of some sort.
Given that it's a 16-bit value, it can't be the size of the whole file, but could indicate the number of compression blocks, the size of the compressed data to read or the size of the uncompressed data to write.
These hypotheses were evaluated one by one, and led to the discovery of an
anomaly: the compressed file had 0x00 0x00 at offset 0x623f (at the same
time identifying the number as big-endian):
╭──
00006230: 07 30 0907 cc13 6465 6c65 0760 2204 30│00 .0....dele.`".0.
──╮ ╰──
00006240: 00│48 2589 c407 6025 416c 6c06 1c6c 73 07 .H%...`%All..ls.
──╯
This number is followed by 0x4825, and there is another pair of zeroes at
0x623f + 2 + 0x4825 = 0xaa66:
╭────╮
0000aa60: 2b60 15fe 0114│0000│4199 4010 6500 1353 +`......A.@.e..S
╰────╯
Apparently the 0x0000 identifies the end of a subsection, and the following
word is the beginning of the next section, indicating its respective length in
bytes.
I initially assumed that 0x0000 is a special marker between subsections,
and I needed to manually count bytes and abort the decompression before
reaching it, but it turns out that it actually is just the final 0x0000
token that tells the decompressor to finish.
Subsection sizes after decompression
The subsection sizes appear to be rather random, but Igor pointed out a pattern in the decompressed sizes, at a time when the file didn't decompress cleanly yet, and we were struggling for new ideas:
BTW, it seems the first compressed section decompresses to exactly 0x8000 bytes
That made me check out the decompressed sizes for all subsections of
chunk-05 and to find a deeper meaning:
*** wrote 32768 bytes
*** wrote 24576 bytes
*** wrote 24576 bytes
...
*** wrote 24576 bytes
*** wrote 24462 bytes 👈🤯
*** wrote 24576 bytes
...
The first one was clearly special, most of the following subsections were 24576 bytes, and some were slightly different. A deeper look into the 24462-byte-section led to the realization that the previous approach at counting variable-length lengths was not correct, and that it is indeed "add bytes until !=255".
Plain-text subsections
That made all the subsections until offset 0x316152 decompress cleanly,
giving nice equally-sized 24576-byte outputs.
However, the subsection size at offset 0x316152 was 0xe000, a rather
strange value. I had a suspicion that the MSB in the subsection size was
actually a compression flag, and 0xe000 & 0x7fff = 24576 - the typical
uncompressed subsection size!
The suspicion came from looking at chunk-03.bin, which begins with a
subsection of 0x800c, followed by 14 bytes, of which most are zero:
00000000: 800c 7047 0000 0300 0000 0000 0000 0000 ..pG............
That could mean "uncompressed subsection", size 0x0c = 12, followed by
an 0x0000 end-of-file marker.
By applying FAFO it was determined that the uncompressed subsections also need to be fed into the lookup window, and the decoder behaved excellently:
$ m7mu-decompress.py -d -O0 chunk-01.bin |grep "\* wrote " |uniq -c
1 *** wrote 32768 bytes
253 *** wrote 24576 bytes
1 *** wrote 17340 bytes
This allowed to decompress the firmware for the NX cameras, but there is still
one failure case with chunk-04.log of the RS_M7MU.bin file. The decoder
bails out after writing:
*** 00000000 Copying uncompressed section of 0 bytes ***
That's not quite right. The first subsection begins with 0x8000 which,
according to our understanding, should either mean "0 uncompressed bytes" or
"32768 compressed bytes". Neither feels quite right. Given that the
(compressed) first subsection in all other files decompresses to 32768 bytes,
this is probably a special case of "32768 uncompressed bytes", which needs to
be added to the decoder:
subsection_len = struct.unpack(">H", f.read(2))[0]
if subsection_len == 0x0000:
return # reached end-of-section marker
elif subsection_len >= 0x8000:
# uncompressed subsection
uncompressed_copy_len = (subsection_len & 0x7fff)
if subsection_len == 0x8000:
# work around for RS_M7MU chunk-04
uncompressed_copy_len = 0x8000
This was the last missing piece to decompress all firmware files! Having those, Igor identified the compression algorithm as the very obscure Fujitsu RELC.
Fujitsu RELC history
There are still a few details available about Fujitsu RELC, mostly in Japanese. There is a 2014 Arcmanager software library pamphlet, mentioning both ESLC (Embedded Super Lossless Compression) and RELC (Rapid Embedded Lossless data Compression):

Furthermore, their 2011 ARM Cortex Design Support factsheet outlines a RELC hardware block connected via AHB:
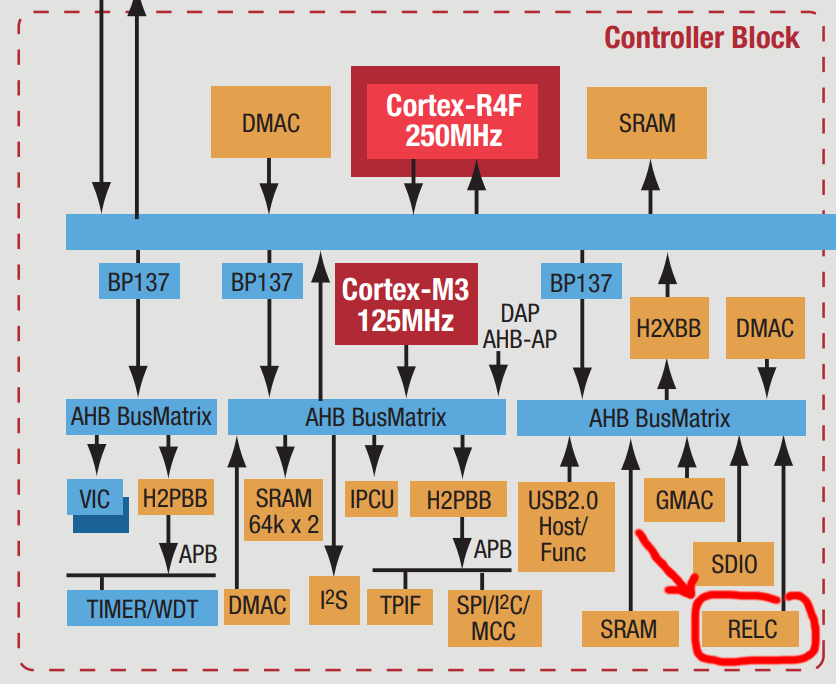
The Arcmanager portal gives some more insights:
- the (Windows) Arcmanager was introduced in 2002 and last updated in 2022.
- there is a sample self-extracting EXE archive with some example Visual Basic / Visual C code
- the algorithm was first published by Noriko Itani and Shigeru Yoshida in an October 2004 programming magazine as SLC/ELC
The original submission already makes use of 13-bit offsets and 3+N*8 bit offset encodings:
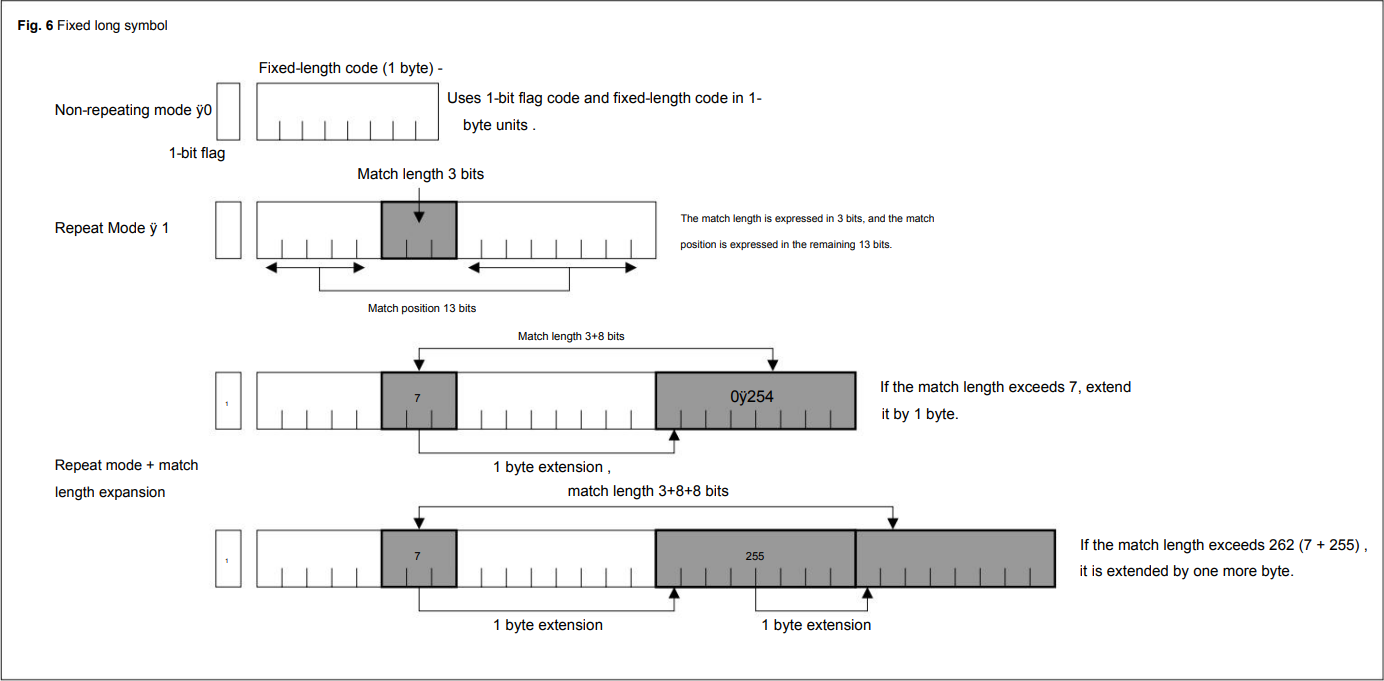
Unfortunately, this knowledge was only unlocked after understanding the algorithm solely by analyzing the Samsung firmware files. However, the use of a RELC hardware block can be confirmed from the RELC-related strings in the firmware files:
# Set RELC AHB Bus Clock Stop in CLKSTOP_B register
USAGE>top clock set_reg clkstop_b RELCAH value
USAGE>relc set [inbuf/inbufm/refbuf] [in_addr] [in_size] [out_addr
# Set and Start RELC normal mode.(Async type)
# Set and Start RELC descriptor mode.(Async type)
# Set and Start RELC normal mode.(Sync type)
# Set and Start RELC descriptor mode.(Sync type)
Summary
This rather long and winding story goes through different layers of the NX mini, NX3000/NX3300 and Galaxy K-Zoom firmware firmware files, analyzing and understanding each layer, and arriving at the discovery of a hardware accelerator embedded into the Fujitsu CPUs powering the Samsung cameras.
The ultimate file structure is as follows:
- a 1024-byte M7MU header pointing at the following sections:
- a "writer" (320KB ARM binary, probably responsible for flashing the firmware from SD)
- seven (un)compressed section files (
chunk-0x.bin), each with the following format:- a sequence of subsections, each starting with a compression flag bit and a 15-bit length, with the compressed subsections containing an RELC/LZSS compressed stream with two-byte bitmasks and two-byte/variable-length tokens, making use of an 8KB window
- a
0x0000end-of-section marker
- one rather large
SF_RESOURCEfilesystem with additional content
The firmware file dumper to extract the writer, the chunks and the
SF_RESOURCE was described in the
M7MU Firmware File Format
post and can be downloaded from
m7mu.py.
The final version of the decompressor, implementing all of the above discoveries, can be found in the project repository as m7mu-decompress.py.
Now this can be used for understanding the actual code running on these cameras. Stay tuned for future posts!