Für die Entwicklung eines QoS-Routing-Protokolls für mobile Ad-Hoc-Netzwerke müssen zunächst die Grundlagen beleuchtet werden. Dazu dient dieses Kapitel.
Zuerst wird geklärt, was mobile Ad-Hoc-Netzwerke auf WLAN-Basis sind und wie sie sich von herkömmlichen Rechnernetzen unterscheiden. Danach werden Routing-Protokolle und QoS-Protokolle für mobile Netzwerke vorgestellt, um den Stand der Entwicklung in diesem Bereich aufzuzeigen.
In einem eigenen Abschnitt wird das Intracluster-Protokoll vorgestellt, das als Basis für diese Arbeit dient. Schließlich wird auf die bei der Entwicklung eingesetzte Simulationsumgebung eingegangen.
Ein mobiles Ad-Hoc-Netzwerk (MANET) ist ein drahtloses Computer-Netzwerk, welches sich durch mehrere Eigenschaften von gewöhnlichen drahtlosen und drahtgebundenen Netzwerken abgrenzt.
Das wichtigste Kriterium von MANETs ist das Fehlen einer festen Infrastruktur, wie sie z.B. beim Mobilfunk als Verbindung der Basisstationen untereinander realisiert ist. MANETs bestehen ausschließlich aus sich selbst konfigurierenden mobilen Knoten und benötigen zu ihrem Betrieb keine weiteren Voraussetzungen. Des Weiteren sind die Teilnehmer eines MANETs meist nicht in der Lage, durch direkte Verbindungen alle anderen Knoten im Netzwerk zu erreichen und sind deshalb auf die Kooperation der anderen Stationen angewiesen, um mit weiter entfernten Knoten zu kommunizieren.
Hinzu kommt, dass die zur Kommunikation verwendete drahtlose Übertragung fehleranfällig ist und nur geringe Bandbreiten im Vergleich zu kabelbasierten Netzwerken bietet.
Durch die begrenzte Reichweite der Funkübertragung und die Mobilität der Knoten kommt es häufig dazu, dass Stationen keine Verbindung mehr zueinander haben oder neue Verbindungen aufbauen. Dadurch ändert sich die Topologie des Netzwerks auf unvorhersehbare Weise, was den Versand von Daten über mehrere Zwischenstationen (Multi-Hop-Betrieb) erschwert.
Das vom Institute of Electrical and Electronics Engineers (IEEE) als Industriestandard IEEE 802.11 [IEE] herausgegebene Protokoll für drahtlose Netzwerkkommunikation hat sich durch die günstige Fertigung und weite Verfügbarkeit von Endgeräten für die Funkvernetzung in Haushalten und als Medium zum Aufbau mobiler Ad-Hoc-Netzwerke durchgesetzt.
Dieser Standard unterstützt neben dem Infrastruktur-Modus auf Grundlage von festen Basisstationen (Access-Points) auch eine Ad-Hoc-Betriebsart, in der sich Stationen in gegenseitiger Sichtweite dynamisch zu Funkzellen zusammenschließen.
Zur Datenkommunikation spezifiziert der Standard unterschiedliche Modulationsverfahren, die auf zwei lizenzfrei benutzbaren Funkfrequenzbändern Brutto-Datenraten von bis zu 54 Mbit/s erlauben. Im ISM-Band (für Industrial, Scientific and Medical, 2400-2500MHz) sind dabei in Europa 13, in den USA 11 Kanäle mit einem Abstand von 5MHz definiert, die eingesetzt werden dürfen. Da die Übertragungen jedoch mit einer Funkbandbreite von 22MHz stattfinden, können effektiv nur drei Kanäle überlappungs- und störungsfrei parallel genutzt werden. Arbeiten zwei Netzwerke auf sich überlappenden Frequenzen, so funktioniert die Erkennung anderer Sender nicht mehr zuverlässig und die Wahrscheinlichkeit von Kollisionen steigt.
Das zweite Frequenzband, das bei 5100-5700MHz liegt, ist in Deutschland erst Ende 2002 freigegeben worden und darf nur unter bestimmten Auflagen außerhalb geschlossener Räume verwendet werden. Es ist nur der Einsatz im Infrastruktur-Modus mit Access-Points erlaubt, die eine automatische Absenkung der Sendeleistung und automatischen Frequenzwechsel durchführen, wenn sie eine Überlappung mit anderen Nutzern des Frequenzbandes wie militärischen Radaranlagen und Satellitenortungssystemen erkennen. Diese Vorschriften machen die Implementierung der Technik teurer und sorgten bisher für eine geringere Verbreitung. Aus diesem Grund ist das Spektrum aber auch nicht so überlastet, wie das ISM-Band, in dem neben den weit verbreiteten WLANs auch Mikrowellen-Öfen und Bluetooth-Geräte stören können [Tri02].
Die MAC-Schicht (Media Access Control, Sicherungsschicht) des WLAN-Protokolls wurde dem in der PC-Vernetzung üblichen Ethernet nachempfunden, um den Umstieg zu erleichtern. Sie implementiert neben der Direktkommunikation von Knoten auch das Versenden von Broadcast-Nachrichten an alle Teilnehmer. Die Zugriffssteuerung erfolgt über Carrier Sense Multiple Access / Collision Avoidance (CSMA[TK75]/CA) - die Medienzugriff erwünschenden Teilnehmer können erkennen, ob das Medium gerade frei oder besetzt ist (Carrier Sense) und warten im Zweifelsfall bis es für eine zufällig bestimmte Zeit frei ist. Wenn danach niemand anders eine neue Übertragung gestartet hat, können sie senden.
Da das Medium naturgemäß fehleranfälliger ist als Datenkabel, wurden zusätzliche Sicherungsmaßnahmen eingeführt. Dazu gehört die in Hardware durchgeführte Sicherung der Nachrichten-Zustellung bei Punkt-Zu-Punkt-Verbindungen: Jede Nachricht wird vom Empfänger mit einem kurzen Bestätigungspaket quittiert; bekommt der Sender die Bestätigung nicht, so wiederholt er die Aussendung des Datenpakets, was bei Bedarf mehrfach geschieht. Dieses Verfahren bietet zwar erhöhte Zuverlässigkeit bei der Zustellung der Pakete, kann letztere aber nicht garantieren. Außerdem lässt sich die Anzahl der Wiederholungen nur schwer durch eine Anwendung abfragen.
Durch die begrenzte Sende-Reichweite kommt noch das Hidden-Station-Problem [TK75] ins Spiel: Sind drei Knoten A, B und C so angeordnet, dass B, der Mittlere, die beiden anderen empfangen kann, diese sich aber nicht gegenseitig sehen, so können A und C gleichzeitig versuchen, Daten an B zu senden und erzeugen eine Kollision beim Empfänger, die sie aber nicht mitbekommen. Dazu wurde eine weitere Erweiterung eingebaut, bei der der Sender durch ein kurzes RTS-Paket (Ready To Send), das die erforderliche Sendezeit enthält, seine Sendebereitschaft signalisiert. Dieses Paket wird vom Empfänger durch ein CTS (Clear To Send) bestätigt, welches auch die angeforderte Zeit enthält und von allen Stationen in Reichweite des Empfängers empfangen werden kann. Letztere wissen dann, dass das Medium für diese Zeit belegt ist und starten währenddessen keine eigene Übertragung.
Um Daten an ein Gerät zu senden, das sich nicht in unmittelbarer Reichweite befindet, müssen Mittler gefunden werden, die die Informationen weiterleiten. Die Suche nach solchen Mittlern und ihre Verwendung werden unter dem Begriff Routing zusammengefasst. Verfahren, die diese Funktion bereitstellen, nennt man entsprechend Routing-Protokolle. Knoten, die Datenpakete für andere weiterleiten, werden Gateway oder Router genannt. In einem MANET können dabei alle Teilnehmer gleichzeitig auch Gateways für die anderen Knoten sein.
Um zu wissen, wohin die Daten geschickt werden müssen, brauchen die Stationen Kenntnis von der Netzwerkstruktur. In kabelgebundenen Netzwerken ändert sich die Struktur nur selten, so dass auf statische Verfahren wie z.B. manuelle Einrichtung zurückgegriffen werden kann. Mobile Ad-Hoc-Netzwerke weisen dagegen eine sehr dynamische Struktur auf, was eine automatische Rekonfiguration der Knoten notwendig macht.
Die Routing-Protokolle sorgen dabei für den Austausch von Routing-Informationen, also Daten darüber, welche Knoten über welche direkten Nachbarn erreichbar sind. Hat ein Knoten solche Informationen über ein bestimmtes Ziel erlangt, so sendet er das Datenpaket für den Zielknoten an denjenigen seiner Nachbarn, der aus seiner Sicht dem Empfänger am nächsten ist. Dort wird es erneut analysiert und den vorliegenden Informationen entsprechend weitergereicht.
Dabei kann es vorkommen, dass zwei Knoten über unterschiedliche Informationen verfügen und ein Datenpaket immer an den jeweils anderen senden, weil sie glauben, dass dieser dem Ziel näher ist. Solche Routing-Schleifen zu vermeiden, die eine enorme Netzlast nach sich ziehen können, gehört zu den wichtigsten Aufgaben des Routing-Protokolls.
Es ist auch möglich, dass ein Knoten keinerlei Informationen darüber hat, wie er ein Ziel erreichen kann, obwohl eine Verbindung existiert. In diesem Fall kann das Paket überhaupt nicht zugestellt werden. Auch solche Situationen sollte das Routing-Protokoll umgehen.
Ein weiteres Problem, das Routing-Algorithmen zu vermeiden haben, ist das count-to-infinity-Phänomen[Sch98]. Es tritt bei Protokollen ohne vollständiges Weltmodell auf, wenn ein Knoten A, der von seinen Nachbarn B und C zunächst direkt, also mit einem Abstand von 1 Hop, gesehen wird, aus dem Netzwerk verschwindet. Daraufhin entfernen B und C jeweils die direkte Route, glauben aber, über den jeweils anderen Nachbarn noch A erreichen zu können. Dabei propagiert B, dass er A über 2 Hops erreichen kann, da er zuvor von C empfangen hatte, dass C von A nur 1 Hop entfernt ist. C empfängt diese Nachricht und aktualisiert seinen Abstand zu A auf 3 (über B, dessen Abstand angeblich 2 ist). B, der die neue Information von C kriegt, setzt den Abstand auf 4. Das gegenseitige Inkrementieren der Länge setzt sich fort, bis der Maximalwert erreicht ist und die Route gelöscht wird. Dieses Problem führt nicht nur zu sehr lange bestehenden ungültigen Routen, sondern erhöht auch die Netzwerkbelastung durch Routing-Updates und sollte daher vermieden werden.
Im Folgenden wird zunächst ein Klassifizierungsschema für Routing-Protokolle vorgestellt, danach werden ausgewählte Verfahren aufgezeigt, ihre Vor- und Nachteile diskutiert und die Protokolle miteinander verglichen.
Bei der Betrachtung von Routing-Protokollen ist es zunächst sinnvoll, diese nach unterschiedlichen Kriterien zu klassifizieren[Fee99]. Die Strukturierung erfolgt dabei nach Kommunikationsmodell, Scheduling, Struktur und Zustandsinformationen.
Das verwendete Kommunikationsmodell ist ein sehr grundlegendes Kriterium - hierbei geht es darum, ob die Kommunikation auf unterschiedlichen Frequenzen/Kanälen bzw. in unterschiedlichen Ad-Hoc-Zellen stattfindet, oder ob sich alle Teilnehmer auf einem gemeinsamen logischen Kanal befinden.
Bei der Verwendung mehrerer Kanäle können die Stationen über mehrere physikalische Sende- und Empfangseinheiten verfügen, die ihnen die gleichzeitige Arbeit mit mehreren Frequenzen erlauben, um damit Voll-Duplex-Betrieb, bessere Signalisierung oder höhere Bandbreiten zu realisieren. Dies macht sie aber technisch aufwändiger und teurer.
Alternativ dazu können mehrere Kanäle auch vom selben Sender/Empfänger nach einem bestimmten Zeitschema verwendet werden. Dieses Zeitschema muss dann unter den miteinander kommunizierenden Teilnehmern synchron gehalten werden.
Um die Komplexität von Hardware und Software zu beschränken, werden in dieser Arbeit nur Protokolle vorgestellt, bei denen sich alle Knoten in der selben Ad-Hoc-Zelle auf dem selben Funk-Kanal befinden. Dadurch ist sichergestellt, dass die Konnektivität der Teilnehmer einzig von geografischen Parametern wie Entfernung und Hindernissen sowie von potentiellen Störern abhängig ist.
Ein weiteres wichtiges Unterscheidungskriterium ist, ob ein Protokoll proaktiv ist, also alle möglichen Pfade bereits im Voraus berechnet und bei Bedarf sofort Pakete versenden kann, oder ob es reaktiv arbeitet, also erst dann den Pfad zu einem Knoten sucht, wenn eine Verbindung angefordert wird. Proaktives Vorgehen hat den Vorteil, dass beim Versenden von Daten keine hohe Verzögerung zum Ermitteln des Ziels notwendig ist und dass es keine Skalierungsprobleme bei einer hohen Anzahl an Verbindungen gibt. Dagegen werden permanent Routing-Informationen auf dem Medium ausgetauscht, selbst wenn keine eigentlichen Daten zu verschicken sind.
Reaktive Protokolle (auch als on-demand bezeichnet) belasten das Medium dagegen nur dann, wenn auch tatsächlich eine Verbindung aufgebaut werden soll. Dazu verschicken sie Nachrichten an ihre Nachbarschaft, in denen nach dem Pfad zum Zielknoten gefragt wird. Kennt einer der Nachbarn die Route, liefert er sie als Antwort zurück, ansonsten wird die Anfrage immer weiter geleitet. Um die damit verbundene hohe Netzwerklast bei vielen Anfragen zu reduzieren, setzen reaktive Protokolle auf aggressives Caching, also das Zwischenspeichern von Routen, die ihnen einmal bekannt geworden sind.
Es existieren auch Protokolle, die einen hybriden Ansatz implementieren, also einen, der proaktives und reaktives Routing für unterschiedliche Ziele kombiniert. Als Auswahlkriterium dient meist die Entfernung der Ziele vom eigenen Knoten - für die eigene Nachbarschaft im Umkreis von wenigen Hops werden vollständige Routing-Informationen bereitgehalten, weiter entfernte Knoten werden an den Grenzen der Nachbarschaft reaktiv gesucht.
Die Struktur des Netzwerks kann zur Klassifizierung von Routing-Protokollen herangezogen werden. Haben alle Knoten das selbe Verhalten, spricht man von einer einheitlichen oder auch flachen Struktur. Alternativ dazu existieren Nachbar-Auswahl-Protokolle, bei denen jeder Knoten nur einen Teil seiner Nachbarn für Routing benutzt sowie hierarchische Modelle, bei denen einzelne Knoten zusätzliche Steuerungsaufgaben gegenüber anderen Stationen wahrnehmen. Weit verbreitet sind dabei in Cluster aufgeteilte Netze, bei denen jeder Cluster-Head mehrere Clients beaufsichtigt und deren Kommunikation regelt. Diese Hierarchie-Strukturierung kann auch rekursiv vorgenommen werden, wobei Cluster einer Ebene die Stationen der nächsthöheren Ebene bilden.
Man kann Routing-Protokolle auch nach der Art der auf jedem Knoten gespeicherten Informationen unterteilen. Topologie-basierte Protokolle speichern dabei ein Weltmodell oder Teile davon auf allen Knoten und die Knoten verteilen Informationen über ihre eigenen Nachbarschaftsbeziehungen (link-state) an alle.
Dem gegenüber stehen Protokolle, die nur Informationen über die Richtung und den Abstand zu anderen Knoten (distance-vector) austauschen. Damit kann zwar die zu versendende Datenmenge reduziert werden, es treten aber andere Probleme auf, die das Routing erschweren, beispielsweise das count-to-infinity-Phänomen.
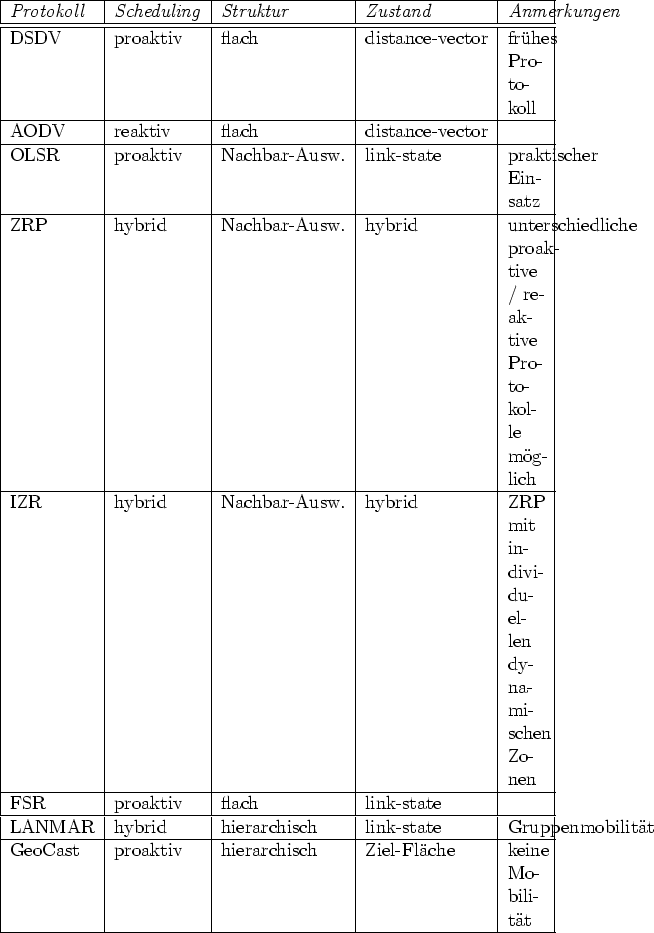
Im Folgenden sollen einige Routing-Protokolle für mobile Netze vorgestellt werden. Es wird insbesondere auf DSDV, AODV, OLSR und FSR eingegangen, die von der IETF (Internet Engineering Task Force, Gremium zur Standardisierung des Internets) als Internet Draft akzeptiert wurden. Um das Feld auszuweiten, werden auch ZRP, IZR als hybride Verfahren, LANMAR als Verfahren mit Gruppenmobilität und GeoCast vorgestellt, welches zwar nicht für MANETs bestimmt ist, jedoch durch die Verwendung geographischer Informationen zu Routingzwecken interessant ist.
Destination Sequenced Distance Vector (DSDV) [PB94,Fee99]
ist ein flaches zielbasiertes proaktives Protokoll. Es trifft Vorkehrungen
gegen Routing-Schleifen, indem Routendaten mit vom Ziel generierten
Sequenznummern![]() versehen
werden und reduziert Fluktuationen durch das Verzögern von Updates über
instabile Pfade. Jeder Knoten versendet periodisch seine Routing-Tabelle,
die die Abstände und Sequenznummern zu jedem Ziel enthält. Zusätzlich versieht
er jede solche Nachricht mit einer eigenen Sequenznummer.
versehen
werden und reduziert Fluktuationen durch das Verzögern von Updates über
instabile Pfade. Jeder Knoten versendet periodisch seine Routing-Tabelle,
die die Abstände und Sequenznummern zu jedem Ziel enthält. Zusätzlich versieht
er jede solche Nachricht mit einer eigenen Sequenznummer.
Die Empfänger von Routing-Nachrichten vergleichen Sequenznummern und Abstände zu allen Zielen und aktualisieren ihre Einträge, falls die Sequenznummer größer oder falls bei gleich großer Sequenznummer der Abstand kleiner ist. Dabei wird jeweils der Sender der Routing-Nachricht als nächstes Gateway zum Ziel eingetragen.
Verliert ein Knoten die Verbindung zu einem Nachbarn, so inkrementiert er
dessen Sequenznummer und setzt den Abstand auf ![]() . Dadurch wird diese
Information von allen Empfängern übernommen (größere Sequenznummer) und der
ausgefallene Knoten entsprechend als nicht erreichbar markiert. Baut letzterer
die Verbindung zum Netz wieder auf, versendet er sein nächstes Update auch mit
einer inkrementierten Sequenznummer, die aber der von seinem Nachbarn bereits
propagierten entspricht. Da aber der Abstand nicht mehr
. Dadurch wird diese
Information von allen Empfängern übernommen (größere Sequenznummer) und der
ausgefallene Knoten entsprechend als nicht erreichbar markiert. Baut letzterer
die Verbindung zum Netz wieder auf, versendet er sein nächstes Update auch mit
einer inkrementierten Sequenznummer, die aber der von seinem Nachbarn bereits
propagierten entspricht. Da aber der Abstand nicht mehr ![]() ist, wird
auch diese Nachricht in die Routing-Tabellen aufgenommen. Durch dieses
,,Fremd-Inkrementieren'' wird das Count-To-Infinity-Problem umgangen.
ist, wird
auch diese Nachricht in die Routing-Tabellen aufgenommen. Durch dieses
,,Fremd-Inkrementieren'' wird das Count-To-Infinity-Problem umgangen.
Ad-Hoc On-Demand Distance Vector (AODV) [PRD99,PRD03] ist ein reaktives flaches zielbasiertes Protokoll. Bei diesem Protokoll flutet ein Knoten, der ein Ziel sucht, ein Anfrage-Paket mit der gesuchten Adresse. Das Fluten besteht darin, dass das Paket von allen Empfängern wiederholt wird, so dass auch deren Nachbarn es empfangen und wiederum weitersenden. Jede Zwischenstation vermerkt den zurückgelegten Pfad im Paket, um eine Rücksignalisierung zu ermöglichen. Sobald der Zielknoten oder ein Knoten erreicht wird, der die Route zum Ziel kennt, kann eine Antwort auf dem aufgezeichneten Pfad zurückgeschickt werden. Auch dabei findet eine Aufzeichnung der Route statt, so dass der Sender diese auswerten und zum Versenden der eigentlichen Daten benutzen kann.
Fällt eine Route aus, auf der aktiv Daten übertragen werden, antwortet der den
Ausfall feststellende Knoten mit einem unangeforderten Routing-Antwortpaket,
das ![]() als Ziel-Abstand enthält. Dieses Paket wird nach und nach bis
zum Sender der Daten propagiert wird, der dann eine neue Route initiieren
kann.
als Ziel-Abstand enthält. Dieses Paket wird nach und nach bis
zum Sender der Daten propagiert wird, der dann eine neue Route initiieren
kann.
Optimized Link State Routing (OLSR) [CeA+03] ist ein proaktives nichteinheitliches Nachbar-Auswahl-Protokoll, bei dem jeder Knoten seinen Link-Status über eine ausgewählte Menge seiner Nachbarn (Multi-point relay, MPR) weiterleitet. Gegenüber dem Fluten wird die Weitergabe der Informationen dabei so begrenzt, dass redundante Übertragungen nicht stattfinden. Das MPR berechnet sich deshalb als die Teilmenge der direkten Nachbarn, die man braucht, um alle Knoten in zwei Hops Entfernung zu erreichen.
Ein Knoten verschickt seine Routing-Daten per Broadcast, womit er alle unmittelbaren Nachbarn erreicht. Weitergeleitet werden die Informationen dann nur noch von den Knoten in seinem MPR, was dabei hilft, die Netzlast zu reduzieren. Zusätzlich wird das Aktualisierungs-Intervall abhängig von der Stabilität des Netzabschnittes variiert, um unnötige Übertragungen einzusparen.
Das Zone Routing Protocol (ZRP) [HPS02a,HPS02b] ist ein Nachbar-Auswahl-Protokoll, dessen Entwicklungsziel darin bestand, die Vorteile von proaktivem (schneller Routenaufbau) und reaktivem (geringe Netzbelastung) Routing zu kombinieren. ZRP besteht entsprechend aus zwei Unterprotokollen: Ein proaktives Intrazone Routing Protocol (IARP) sorgt dafür, dass jeder Knoten seine Nachbarschaft über mehrere Hops kennt. Das reaktive Interzone Routing Protocol (IERP) dagegen kümmert sich um die Suche von Knoten außerhalb der Nachbarschaft. Die Größe der Nachbarschaft (der Zone) wird dabei über den Zonen-Radius bestimmt, der die Anzahl der Hops angibt, über die das IARP ausgeführt wird. Die ideale Wahl der Zonen-Größe hängt vom Einsatzszenario ab, kleinere Zonen sind für dichte Netzwerke mit wenigen sehr mobilen Knoten besser, größere Zonen eignen sich dagegen eher für verstreute Netze, in denen sich viele Knoten langsam bewegen.
Als Optimierung für die Suche von Knoten außerhalb der Zone wird Bordercasting eingesetzt. Bei diesem Verfahren wird die Anzahl der Übertragungen minimiert, die für einen Broadcast einer Nachricht an der eigenen Zonengrenze notwendig sind.
An Stelle von IARP und IERP können auch andere proaktive bzw. reaktive Protokolle eingesetzt werden, um ein hybrides Zonenrouting zu erzielen. Das Prinzip von ZRP ist dabei übertragbar, wenn das reaktive Protokoll an die Bordercast-Möglichkeit angepasst wird.
Mit Independent Zone Routing [SPH04] existiert eine Optimierung von ZRP, bei der jeder Knoten über einen eigenen Zonenradius für die Unterscheidung zwischen proaktivem und reaktivem Protokoll verfügt. Dieser Radius wird dezentral in Abhängigkeit von der Mobilität der Nachbarschaft bestimmt. Auf diese Weise legt jeder Knoten seine eigene Zone fest. Kompliziert wird es allerdings dadurch, dass jeder Teilnehmer seine Informationen an alle Knoten verschicken muss, in deren Zone er sich befindet - daher müssen die Routing-Updates unterschiedliche Strecken zurücklegen, die der Knoten aus den ihm zur Verfügung stehenden Informationen bestimmen muss.
Fisheye State Routing (FSR) [PGC00] ist ein proaktives Routing-Protokoll mit flacher Struktur. Das Prinzip leitet sich vom Auge eines Fisches ab, das im Brennpunkt eine sehr hohe Detaildichte hat, die mit zunehmendem Abstand vom Brennpunkt abnimmt. Bei FSR wird das Prinzip so umgesetzt, dass ein Knoten sehr präzise Informationen über seine Nachbarschaft hat, die mit zunehmendem Abstand ungenauer und älter werden. Dazu werden die Link-Daten anderer Knoten in desto größeren Intervallen übertragen, je größer der Abstand zu diesen Knoten ist. Jeder Knoten hält dabei eine gesamte Karte der Topologie vor, die aktuelle Verbindungen aus seiner Nachbarschaft beschreibt, während weiter entfernte Verbindungen unpräzise dokumentiert sind. Dieser Nachteil wirkt sich in der Praxis allerdings wenig aus, da Pakete, die ihrem Ziel näher kommen, auf Knoten mit immer präziseren Routing-Informationen stoßen und damit präziser weitergeleitet werden können.
Interessant ist auch das Landmark Ad Hoc Routing Protocol (LANMAR) [PGH00]. Dieses hybride hierarchische Verfahren ist auf Gruppenmobilität (ursprünglich im militärischen Bereich) ausgerichtet und setzt dazu Landmarks (Orientierungspunkte) ein, wobei jede Gruppe über einen eigenen Landmark verfügt und jeder Teilnehmer die Pfade zu allen Mitgliedern seiner Gruppe und zu allen Landmarks proaktiv bezieht. Will ein Knoten mit einem Teilnehmer einer anderen Gruppe kommunizieren, so schickt er die Nachrichten an den Landmark der Zielgruppe. Sobald die Datenpakete diese Gruppe erreichen, werden sie mit Hilfe der lokalen Routing-Tabellen weitergeleitet. LANMAR reduziert die Größe der Routing-Tabellen und den Verwaltungsaufwand, funktioniert allerdings nur dann zufrieden stellend, wenn die Gruppen sich geschlossen bewegen - verteilen sich die Knoten nach anderen Mustern, oder entfernt sich ein Landmark von seiner Gruppe, sinkt die Effizienz rapide.
Ein Verfahren, das zusätzliche geografische Informationen aus dem GPS (Global Positioning System zur satellitengestützten Positionsbestimmung) für Routing verwendet ist GeoCast. Dabei werden die Ziele nicht über Knotenkennungen, sondern über den Aufenthaltsort der Knoten bestimmt: Die Adressierung der Datenpakete geschieht anhand von Punkten im Koordinatensystem, kreisförmigen oder durch Polygone beschriebenen Flächen. Die Auslieferung erfolgt an alle Stationen, die sich im Zielbereich befinden.
GeoCast-Router sind hierarchisch angeordnet und besitzen Zielbereiche, für die sie zuständig sind und deren Koordinaten sie kennen. Empfängt ein GeoRouter ein Datenpaket, das sich mit seinem Zuständigkeitsbereich überschneidet, sendet er es in den entsprechenden Bereich. Fallen Teile oder die gesamte Zielfläche nicht in den von ihm abgedeckten Raum, so schickt er die Nachricht zusätzlich an den nächsthöheren Router in der Hierarchie, der sie analog weiterverteilt. Allerdings ist GeoCast nicht auf Knotenmobilität ausgelegt - die Zielbereiche und Routing-Tabellen enthalten nur statische Koordinaten. Mit der Verfügbarkeit günstiger und stromsparender GPS-Empfänger wird die Nutzung von Geo-Koordinaten zur Routing-Unterstützung in MANETs allerdings auch praxistauglich.
Im vorhergehenden Abschnitt ist eine kleine Auswahl von unterschiedlichen Routing-Protokollen präsentiert worden (Tabelle 2.1). Eine vollständige Übersicht würde den Rahmen dieser Arbeit sprengen, jedoch sollte dieser Abschnitt für einen Überblick über die wichtigsten Protokolle und die bei solchen Protokollen möglichen Konzepte genügen.
DSDV und AODV, die ersten von der IETF als Internet Draft akzeptierten Protokolle, zeigen die Migration der bis dahin in drahtgebundenen Netzwerken üblichen proaktiven (DSDV) bzw. reaktiven (AODV) Vorgehensweise auf MANETs. Sie bieten die Grundlage für die Entwicklung zahlreicher neuerer Protokolle. OLSR und FSR versuchen, die Netzwerkbelastung durch Topologie-Daten zu verringern, indem sie die zu versendende Informationsmenge verringern. ZRP und IZR kombinieren reaktive und proaktive Arbeitsweisen für unterschiedliche Ziel-Entfernungen, um so die Vorteile der beiden Routing-Typen zu vereinen. LANMAR optimiert die Menge der Topologie-Daten ausgehend von der Annahme, dass bestimmte Knoten-Gruppen sich gemeinsam bewegen und man alle Knoten innerhalb ihrer Gruppe wiederfinden kann. GeoCast verwendet statt normaler Zieladressen geographische Koordinaten und ein hierarchisches Modell, um Datenpakete an Punkte oder Flächen auf der Erde auszuliefern, erlaubt aber keine Mobilität.
Es ist zu erkennen, dass die Entwickler der Protokolle unterschiedliche Ziele verfolgt haben und die Verfahren ihre Daseinsberechtigung in unterschiedlichen Szenarien besitzen. Proaktive Protokolle eignen sich besser für Netze, in denen viele unterschiedliche Knoten miteinander kommunizieren und die Mobilität nicht sehr hoch ist, reaktive sind dagegen besser geeignet, wenn sich viele Knoten bewegen und dafür nicht so häufig Verbindungen aufgebaut werden. Hybride Verfahren versuchen, den Vorteil der beiden Methoden zu kombinieren, indem sie diese jeweils für das passendere Szenario einsetzen.
Welches Routing-Protokoll eingesetzt wird, hängt im Endeffekt stark von den Anforderungen ab, die man an ein Netz stellt. Dadurch jedoch, dass einige Protokolle nicht vollständig implementiert sind, der Code häufig nicht öffentlich verfügbar ist, unterschiedliche Verfahren z.T. auf unterschiedliche MAC-Schnittstellen setzen und die meisten Evaluierungen nur als Simulationsergebnisse vorliegen, ist ein direkter Vergleich der Protokolle im eigenen Einsatzszenario fast unmöglich. Die Auswahl des eigenen Protokolls muss sich deswegen hauptsächlich auf theoretische Betrachtungen stützen.
Für einige Anwendungen ist es erforderlich, nicht nur Pakete zwischen entfernten Stationen übertragen zu können, sondern auch bestimmte Anforderungen an die Verbindung zu stellen. Während ein Dateitransfer je nach verfügbarer Bandbreite früher oder später abgeschlossen ist, erfordert eine digitale Sprachverbindung eine zugesicherte Mindestbandbreite. Kann diese Bandbreite nicht gewährleistet werden, lässt sich eine unnötige Belastung des Netzes dadurch vermeiden, dass die Verbindung gar nicht erst aufgebaut wird. Verändert sich die verfügbare Bandbreite im Betrieb, so sollte das der Anwendung signalisiert werden, damit diese sich daran anpassen kann - im Falle einer Sprachverbindung könnte ein Codec mit höherer Sprachqualität und höherer erforderlicher Bandbreite gewählt werden.
Ein QoS-Routing-Protokoll hat die Aufgabe, entsprechend den Anforderungen einer Anwendung an die Bandbreite und die maximale Latenz einen Pfad zum Ziel zu finden, der die Kriterien erfüllt, oder die Nichterfüllbarkeit zu signalisieren. Es muss dafür sorgen, dass auf den Gateway-Knoten Reservierungen für diese Verbindung vorgehalten werden und dass bei Ausfällen entweder alternative Pfade gefunden werden oder die Anwendung benachrichtigt wird.
Zu den auf diese Weise realisierbaren und überwachbaren Anforderungen gehört neben der Bandbreite der Verbindung auch die maximale Paket-Verlustrate. Dazu zählen auch die Latenz, also die Zeit zwischen dem Versand und dem Empfang der Pakete und der Jitter, also die Varianz der Paketlaufzeiten.
Für das Quality-Of-Service-Management in Netzwerken existieren zwei grundsätzliche Herangehensweisen.
DiffServ (eine Abkürzung für Differentiated Services, [BBC+98]) ist eine QoS-Architektur für große Netze wie das Internet. Der Gedanke dahinter besteht in der Aufteilung des Datenverkehrs in unterschiedliche Klassen und die Zuordnung von QoS-Eigenschaften und Maximalwerten zu diesen Klassen.
Die genauen Parameter werden dabei in Service Level Agreements zwischen Service-Providern und ihren Kunden festgelegt, die Durchsetzung der Klasseneigenschaften erfolgt auf den Grenz-Routern der Service-Provider. Die Klassen werden als Richtlinie verwendet, welche Pakete bei einer Netzwerküberlast verzögert bzw. verworfen werden können und welche Daten mit Vorrang zu versenden sind.
Da DiffServ den Datenverkehr in Klassen ordnet, ist es praktisch unmöglich, Ende-zu-Ende-Qualitätsgarantien zu geben. Dies wird noch weiter erschwert, wenn der Datenverkehr über unterschiedliche Provider läuft und damit Teil unterschiedlicher QoS-Klassen werden kann. Eine Rückmeldung an die Anwendung findet auch nicht statt, sondern muss vom Empfänger über die Analyse der empfangenen Pakete realisiert werden.
IntServ (Integrated Services [BCS94]) ist im Gegensatz zu DiffServ feingranular ausgelegt. Die Regulierung findet auf Verbindungsebene statt und alle Anwendungen, die QoS-Garantien brauchen, müssen diese vor Aufbau der Verbindung anfordern. Dazu ist es erforderlich, dass jeder Router in dem Netzwerk das QoS-Verfahren implementiert und alle durch ihn führenden Verbindungen erfasst.
Mit IntServ ist ein deutlich höherer Netzwerk-Overhead durch die Reservierung und Erhaltung von QoS-Verbindungen verbunden, der aber im Gegenzug dafür sorgt, dass die Anforderungen der Anwendungen pro Verbindung durchgesetzt und gesichert werden können. Sind die Bedingungen für die QoS-Verbindung nicht gegeben, so findet eine entsprechende Benachrichtigung der Anwendung statt, welche ihr Verhalten auf die neue Situation einstellen kann.
Im Bezug auf MANETs stellt die Implementierung von IntServ eine besondere Herausforderung dar, weil dort nicht nur die Bandbreiten der bestehenden Pfade sondern auch Pfadänderungen und mobilitätsbedingte Unterbrechungen in Betracht gezogen werden müssen.
Bei den IntServ-Protokollen kann man weiterhin danach unterscheiden, ob die QoS-Signalisierung in-band, also als zusätzliches Feld in den übertragenen Datenpaketen, oder out-of-band, also in Form eigenständiger Nachrichten stattfindet. Erstere bietet einen geringeren Overhead, allerdings besteht keine Möglichkeit, QoS-Garantien für eine Verbindung von Anfang an zu gewährleisten - diese können erst bei bestehendem Datenaustausch verhandelt werden.
Es gibt QoS-Protokolle, die auf einem existierenden Routing-System aufsetzen und solche, die eine Kombination aus QoS und Routing anbieten - letztere haben den Vorteil, dass die Pfad-Daten für beide Zwecke verwendet werden können, so dass alternative Routen unter Umgehung überlasteter Knoten gefunden werden können.
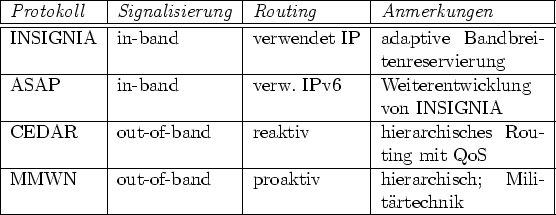
Im Folgenden werden einige QoS-Protokolle für mobile Ad-Hoc-Netze vorgestellt. Dabei werden INSIGNIA und ASAP als reine QoS-Verfahren für bestehende Netze behandelt, es wird auf CEDAR als QoS-Routing-Protokoll und MMWN eingegangen, welches dem militärischen Bereich entstammt.
Ein IntServ-QoS-Verfahren, welches mit bestehenden Routing-Algorithmen kombiniert werden kann ist INSIGNIA[LAZC00]. Dieses Verfahren setzt auf IP-Netzwerken auf, indem zusätzliche Header für IP-Pakete eingeführt werden, die QoS-Parameter übertragen. Die Reservierung erfolgt in-band, also wenn die eigentliche Verbindung bereits aufgebaut ist. Dazu fügt der Sender einen INSIGNIA-Header in ein zu versendendes Paket ein, und gibt darin den Reservierungswunsch sowie die gewünschte Mindest- und Höchstbandbreite an. Durch dieses Verfahren ist der Mehraufwand für das Protokoll minimal.
Die Gateway-Knoten versuchen anhand dieser Angaben eine Reservierung der Bandbreite durchzuführen. Steht weniger als die Maximalbandbreite zur Verfügung, ändern sie die im Header vermerkten Anforderungen ab. Haben sie nicht genügend Bandbreite für die Mindestanforderung, so werden die Pakete als Best-Effort weitergeleitet. Der Empfänger sieht den Status der Reservierung anhand der an ihn übermittelten Header und kann diesen bei Antwortpaketen an den Sender zurückschicken, so dass dieser seine Bandbreite entsprechend anpasst. Daher richtet sich INSIGNIA an adaptive Anwendungen, die in der Lage sind, das Feedback auszuwerten und die verschickte Datenmenge auch zur Laufzeit an die Netzsituation anzupassen.
Die QoS-Header müssen regelmäßig in die Datenpakete eingebettet werden, da es keine Möglichkeit gibt, über Routen-Änderungen informiert zu werden, und Pakete möglicherweise über Gateways umgeleitet werden, die noch keine Reservierung für eine gegebene Verbindung haben. Aus diesem Grund erfolgt die Reservierung auch implizit - ein Gateway-Knoten führt sie durch, sobald er ein Paket mit einem QoS-Header sieht, und verwirft sie, wenn einige Zeit lang keine Pakete dieser Verbindung mehr über ihn verschickt wurden.
Als zusätzliche Maßnahme existieren zwei Paket-Typen: base QoS und enhanced QoS. Diese dienen der Priorisierung von Paketen einer Verbindung in Engpass-Situationen - Pakete mit dem enhanced-QoS-Bit enthalten Zusatzinformationen, die für die Kommunikation zwar relevant, aber nicht essenziell sind, und können somit auf dem Weg verworfen werden.
Als Weiterentwicklung von INSIGNIA wurde ASAP[SXA04] (Adaptive ReServation and Pre-Allocation protocol) vorgestellt. Dieses Verfahren splittet die Bandbreitenreservierung in zwei Phasen auf. In der ersten - wenn ein QoS-Paket vom Sender zum Empfänger geschickt wird - tragen die Gateway-Knoten die erforderliche Bandbreite als weiche Reservierung in ihre Tabellen ein. Diese Bandbreite darf dann nicht für andere Anwendungen reserviert werden, ist aber immer noch für Best-Effort-Daten freigegeben. Wenn die Routen-Reservierung bis zum Empfänger vorgedrungen ist, wird mit dem Antwortpaket ein Signal verschickt, dass die Reservierung nun hart ist. Auf diese Weise ist die Netzbelastung durch unvollständige Routen geringer.
Beide Protokolle sind vom Routing vollständig abgekoppelt, was ihre Funktionsweise benachteiligt - so werden Routen-Änderungen dem QoS-Protokoll nicht explizit mitgeteilt und müssen eruiert werden. Außerdem besteht durch die Trennung keine Möglichkeit, alternative Pfade zu suchen, wenn die direkte Route zum Ziel nicht die erforderliche Bandbreite bietet - die Kommunikation wird lediglich auf Best-Effort-Niveau reduziert.
Ein Verfahren, welches Routing und QoS kombiniert ist CEDAR (Core Extraction Distributed Ad hoc Routing) [SSB99]. Das ist ein reaktives hierarchisches Protokoll, bei dem ein Teil der Knoten zu einem Minimum Dominating Set (MDS) gewählt wird. Das ist die kleinste Menge von Knoten, so dass jeder Teilnehmer höchstens einen Hop bis zum nächsten MDS-Knoten hat. Letztere bilden untereinander den Kern des Netzes und sind über ,,Tunnel'' durch je höchstens zwei normale Knoten miteinander verbunden.
Kennt ein Knoten nicht den Pfad zu seinem Ziel, so schickt er eine Anfrage an seinen dominator, also den ihm benachbarten Kern-Knoten. Dieser leitet das Suchpaket dann an alle anderen Knoten im MDS und bestimmt so den Kern-Pfad zum Dominator des Zielknotens. Neben Routen werden im Kern auch QoS-Informationen verteilt, wobei stabile, langanhaltende Links am weitesten bekanntgegeben werden. Der Sender kann aus den Informationen, die er von seinem Dominator bekommt, eine mögliche Bandbreite für die Übertragung bestimmen, die er in Abstimmung mit dem Dominator in einen Pfad mit gesicherter Bandbreite umwandelt, um diesen für die Daten zu benutzen.
Ein weiteres Beispiel für die Kombination von QoS und Routing ist MMWN (hierarchically-organized Multihop Mobile Wireless Networks for quality-of-service support). Dieses hierarchische link-state-basierte Verfahren ordnet mobile Knoten Zellen zu, wobei jede Zelle einen cellhead besitzt, der ein direkter Nachbar aller zur Zelle gehörenden Knoten ist. Zellen können sich zu Clustern zusammenschließen, welche wiederum rekursiv noch größere Cluster bilden können. Die Knotenadressen bilden diese Hierarchie ab, indem sie aus den Cluster-Bezeichnern von der höchsten Schicht an zusammengesetzt werden. So ist die Adresse von Knoten X, der sich in Zelle U von Cluster A befindet A.U.X.
Neben den Link-Zuständen werden immer auch Dienstgüte-Informationen übertragen, dabei wird der Datenaustausch auf den unmittelbar davon betroffenen Bereich begrenzt. Bei der Routenberechnung werden die Dienstgüte-Anforderungen der Anwendung berücksichtigt, die neben der Pfadlänge eine entscheidende Rolle spielen. Zur Vermeidung von Routing-Schleifen durch veraltete Informationen wird auf eine Kombination aus Source-Routing und Destination-based-Routing gesetzt:
Der Sender setzt die Route soweit ihm bekannt in das Datenpaket - für den eigenen Cluster ist der Pfad dabei vollständig, über den Rest der Strecke enthält er nur Informationen, welche Hierarchie-Ebenen wie zu traversieren sind. Die detaillierten Informationen werden von den Gateways auf dem Weg vervollständigt.
Jeder Cluster besitzt einen location manager, der den Aufenthaltsort aller Knoten im Cluster kennt und Unterstützung bei der Pfadsuche anbietet. Dieser erlaubt es, auf Knotenbasis die Aktualisierungsintervalle entsprechend der Mobilität und Anfragehäufigkeit der Knoten anzupassen. Die Location Manager ermitteln auch die Ziel-Adressen für Anfragen aus dem Cluster, also die Anordnung der Ziele in der gesamten Hierarchie.
MMWN bietet zusätzliche Mechanismen zur Änderung bestehender Verbindungen an, um Dienstgüte trotz der Knotenmobilität zu gewährleisten. So können Teilstrecken einer Verbindung umgeleitet oder Pakete an mehrere mögliche Aufenthaltsorte des Zielknotens gesendet werden. Zusätzlich erlaubt das Verfahren die Überwachung und Änderung der Link-Eigenschaften - z.B. das Anheben der Sendesignalstärke, wenn die Verbindungsqualität unter einen gewissen Wert sinkt.
Neben Dienstgüte und Verbindungsreparaturen bietet MMWN auch Multicast-Unterstützung an. Dazu existiert in jedem Cluster ein multicast manager, der für die Verwaltung der Multicast-Gruppen und das Hinzufügen und Entfernen von Knoten zu diesen zuständig ist.
Dadurch, dass MMWN für militärische Zwecke entwickelt worden ist, ist eine Übertragung auf zivile Technik allerdings nur eingeschränkt möglich, da dort nicht nur andere Regulierungsvorschriften für Sendeleistung und weitere Betriebsparameter gelten, sondern auch begrenzte Anschaffungskosten die Möglichkeiten eingrenzen.
Bei den QoS-Verfahren gilt um so mehr das, was schon für die Routing-Protokolle gesagt wurde: Jedes Verfahren wurde ausgehend von einem bestimmten Szenario entwickelt und funktioniert in anderen Situationen nicht optimal. Die Auswahl eines Verfahrens oder die Kombination unterschiedlicher Methoden für eigene Zwecke muss daher sorgfältig abgewogen werden.
In Tabelle 2.2 findet sich eine Übersicht über die QoS-Protokolle. Während INSIGNIA und ASAP die QoS-Signalisierung in die eigentlichen Datenpakete einbetten, weil sie das Routing der Pakete nicht beeinflussen können und bei scheiternden Reservierungen auf Best-Effort zurückschalten, kombinieren CEDAR und MMWN Routing und QoS. Das erlaubt ihnen, Pfade nicht nur nach ihrer Länge, sondern auch nach den Qualitätsanforderungen der Anwendung auszuwählen. Beide bauen eine Routing-Hierarchie auf, die bestimmte Knoten mit Zusatzaufgaben zur Pfad-Suche und zum Monitoring der Umgebung bestimmt, und die normale Clients beim Verbindungsaufbau unterstützt.
Um zuverlässig Daten zwischen entfernten Stationen in einem MANET auszutauschen, müssen zwei Voraussetzungen erfüllt sein. Zum einen müssen Knoten in der Lage sein, zuverlässig Pakete an ihre unmittelbaren Nachbarn zuzustellen und Fehler bei der Zustellung zu erkennen. Zum anderen brauchen sie eine konsistente Sichtweise auf ihre Nachbarschaft, die die tatsächliche Konnektivität möglichst gut abdeckt.
Um beide Ziele zu erreichen, wurde in einer vorangegangenen Arbeit der Arbeitsgruppe ,,Echtzeitsysteme und Kommunikation'' das Intracluster-Protokoll entwickelt. Dieses Protokoll dient der selbständigen Anordnung der mobilen Knoten zu Clustern, der Synchronisierung des Paketversands innerhalb eines Clusters und der Kollisionsvermeidung von unterschiedlichen Clustern. Es implementiert ferner reliable Broadcast, also die zuverlässige Auslieferung von Datenpaketen an alle Cluster-Mitglieder. Durch die Regelung des Medienzugriffs tritt das Protokoll gegenüber seinen Anwendungen als erweiterte MAC-Schicht auf.
In einem mobilen Ad-Hoc-Netzwerk müssen sich die Knoten selbst organisieren. Dazu verfügen sie über keine anderen Informationen als die Datenpakete, die sie von ihren unmittelbaren Nachbarn empfangen können.
Beim vorliegenden Clustering-Schema können Knoten einen von zwei Zuständen annehmen. Ein Cluster-Head ist eine Station, die einen Cluster leitet, ein Client ist einem oder mehreren Heads untergeordnet. Um die Existenz des Clusters anzuzeigen, versendet ein Head in regelmäßigen Zeitabständen Informationspakete (Invite), die die Cluster-Id und die Liste der Clients enthalten.
In Abbildung 2.1 sieht man eine typische Anordnung von Cluster-Heads und Clients. Cluster 1 (die Cluster-Id entspricht der Knoten-Kennung des Heads) ist dabei durch eine schraffierte Ellipse gekennzeichnet, zu ihm gehören neben dem Head (Knoten 1) die Clients 2, 3, 4 und 7.
Die Cluster-Heads können dabei jeweils nur mit Clients verbunden sein, welche wiederum nur Verbindungen mit Heads eingehen können. Direktverbindungen zwischen Clients und Clients, bzw. zwischen Heads und Heads sind nicht zugelassen.
Kommunikation zwischen Clustern ist damit über Gateway-Knoten, also solche Clients, die zu mehreren Heads verbunden sind, vorgesehen. Im Bild sind das die Stationen 3, 7, 8 und 9.
Wird ein Knoten zum ersten Mal aktiviert, startet er im Client-Betrieb und wartet zunächst auf Invite-Nachrichten. Hört er einen Cluster-Head in seiner Reichweite, so versucht er, dessen Cluster beizutreten. Dies geschieht durch ein JoinRequest-Paket an den Head, welches unmittelbar nach einem Invite zu verschicken ist. Wird der Knoten aufgenommen, so wird er im nächsten Invite-Paket aufgeführt und vom Head regelmäßig kontaktiert.
Dabei kann ein Client auch mit mehreren Cluster-Heads verbunden sein - in dem Fall kann er als Gateway-Knoten für Multi-Hop-Übertragungen eingesetzt werden. Die Anzahl der Cluster, in denen ein Client gleichzeitig sein kann, ist dabei durch eine Konstante begrenzt, genauso wie die Clustergröße.
Hört ein Client keine Heads oder kann er zu keinem Cluster beitreten (z.B. weil dieser voll ist), so schaltet der Knoten nach einer bestimmten Wartezeit in den Head-Modus und verschickt eigene Invite-Pakete. Daraufhin versuchen alle Clients, die die Nachrichten empfangen, sich mit ihm zu verbinden.
Eine Maßnahme zur Reduktion der Clustermenge besteht in der Verschmelzung mehrerer Cluster zu einem - dabei versucht ein Head, der (z.B. durch eigene Bewegung) in Reichweite eines anderen Clusters kommt, zu dessen Client zu werden. Ist das nicht möglich, weil die beiden Heads zusammen mehr Clients haben, als einer verwalten kann, so findet keine Verschmelzung statt. Da die Entscheidung, welcher der beiden Heads zum Client werden soll, verteilt erfolgen muss, wurde dafür ein Kriterium herangezogen, welches beide Heads überprüfen können: Das Alter der Cluster, welches auch im Invite-Paket auftaucht. Um die Stabilität von lange bestehenden Verbindungen zu fördern, wird deshalb der jüngere Cluster aufgelöst.
In einem Cluster erfolgt die Kommunikation streng nach einem Zeitschema. Dieses besteht aus Runden, wobei jede Runde aus einer bestimmten Anzahl von Zeitschlitzen besteht. Das Zeitschema wird vom Head vorgegeben, indem er in jeder Runde Nachrichten verschickt. Dabei kann er zwei Arten von Paketen aussenden - einmal pro Runde generiert er ein Invite-Paket, welches von noch nicht verbundenen Stationen verwendet werden kann, um dem Cluster beizutreten. In allen weiteren Zeitschlitzen befragt er seine Clients der Reihe nach mit einem Poll-Paket, auf das sie mit einem Client-Data-Frame mit den zu versendenden Daten antworten.
Einen Zeitschlitz nutzt der Head, um seinen lokalen Anwendungen die Möglichkeit zum Datenversand zu geben. Dazu trägt er sich selbst als Pseudo-Client in die Liste ein und führt jede Runde einen lokalen Poll durch, den er selbst beantwortet. Die Anfrage wird dabei auf dem realen Medium verschickt, da sie auch für andere Clients relevante Daten enthält.
Damit ein Client, der in mehreren Clustern ist, nicht das Schema des einen
Clusters stört, während er mit dem anderen kommuniziert, lässt jeder Head
zwischen den tatsächlich verwendeten Zeitschlitzen jeweils einen festen
Zeitabstand von ![]() Slots, in dem andere Cluster arbeiten können. Sieht ein
Head, dass ein anderer Cluster in seinem Zeitschlitz kommuniziert, ,,springt''
er einfach einen Zeitschlitz weiter und entgeht auf diese Weise Kollisionen.
Hierdurch kann ein Client gleichzeitig in bis zu
Slots, in dem andere Cluster arbeiten können. Sieht ein
Head, dass ein anderer Cluster in seinem Zeitschlitz kommuniziert, ,,springt''
er einfach einen Zeitschlitz weiter und entgeht auf diese Weise Kollisionen.
Hierdurch kann ein Client gleichzeitig in bis zu ![]() Clustern sein, die sich
das Medium teilen.
Clustern sein, die sich
das Medium teilen.
Da die Cluster-Heads keine synchronisierten Uhren haben, kann es vorkommen, dass sich ihre Zeitschlitze nur teilweise überlagern. Um diesem Problem vorzubeugen, darf nur während der ersten Hälfte eines Zeitschlitzes kommuniziert werden. Die zweite Hälfte dient als Synchronisationspuffer und zum Erkennen von Zeitschlitzkollisionen.
Da die Clients sich nicht immer gegenseitig sehen, hat der Head die Aufgabe, alle Datenpakete, die er von einem Client empfängt, an die anderen weiterzuleiten. Dies geschieht, indem die Client-Daten im Poll-Paket des nächsten Slots eingebettet werden. Damit alle teilnehmenden Stationen die Nachricht empfangen können, wird der Poll als Broadcast-Nachricht versendet.
Ein weiterer Grund für die Verwendung der Broadcast-Übertragung ist die Tatsache, dass die MAC-Schicht der meisten WLAN-Karten eine eingebaute Sendewiederholung für Unicast-Pakete hat, die sich nicht abschalten lässt und die man nicht auswerten kann. Um garantierte Übertragungen bieten zu können, muss der Sender aber wissen, ob die Nachricht angekommen ist oder nicht, bzw. wie viele Sendeversuche benötigt wurden.
Diese Funktionalität wurde daher hardware- und firmwareunabhängig in der Cluster-API implementiert. Jeder Knoten führt hierzu eine Checkliste über die in der letzten Runde empfangenen Pakete. Diese Liste schickt er in Form eins Bit-Feldes mit jedem Paket an den Head mit. Stellt dieser dann fest, dass der Client ein Paket nicht empfangen hat, so fordert er dieses Paket in der nächsten Runde erneut beim Versender an und verteilt es wieder. Kann das Paket drei Mal nicht zugestellt werden, so geht der Head davon aus, dass die Verbindung zum Client zu schlecht ist und entfernt diesen aus dem Cluster.
Im Beispiel (Abbildung 2.2) ist ein Abschnitt der Kommunikation der Cluster-Heads A und C sowie von Client B, der in beiden Clustern ist, dargestellt. Beide Cluster-Heads besitzen noch weitere Clients, die Kommunikation mit diesen wird durch gestrichelte Linien symbolisiert. Nachrichten zwischen A, B und C sind als Pfeile dargestellt.
Im ersten Zeitschlitz verschickt Head A eine Anfrage (Poll) an Client B, der diese mit einem Datenpaket beantwortet. Dabei wird sowohl die Anfrage als auch die Antwort als Broadcast verschickt, das Poll-Paket (mit den Daten des davor befragten Clients) erreicht alle anderen Stationen von Cluster A, die Antwort sehen alle Heads von Client B (also A und C). Auf diese Weise sieht Head C, dass der Zeitschlitz von einem anderen Cluster beansprucht wird, und verzögert u.u. die eigenen Pakete.
Zeitschlitz 2 wird von Head C benutzt, um einen anderen Client zu befragen. Das Poll-Paket erreicht dabei Client B, der die darin enthaltenen Daten auswertet, aber nicht darauf antwortet.
Der dritte Zeitschlitz wird weder von Cluster A noch von C benutzt und könnte von einem weiteren Cluster verwendet werden. Im vierten Zeitschlitz ist schließlich wieder Head A an der Reihe. Im vorliegenden Beispiel ist es für drei Cluster möglich, am selben Ort zu koexistieren und ein Client kann sich in bis zu drei Cluster einbuchen. Dieser Wert wurde aus Gründen der Anschaulichkeit gewählt, im praktischen Einsatz ist er höher.
Zeitschlitz 4 wird von Head A benutzt, um seine lokale Anwendung zu befragen. Dazu versendet er zunächst ein Poll-Paket, in dem er selbst als Empfänger eingetragen ist. Dieses Paket enthält die Daten, die der Head im Zeitschlitz 1 von Client B erhalten hat, und wird an alle Stationen im Cluster gesendet. Danach generiert die lokale Anwendung von A ein Datenpaket, welches aber nicht über das Medium übertragen wird, sondern nur in die Sende-Puffer des Heads kommt (gebogener Pfeil). Dieses Paket wird vom Head in seinem nächsten Zeitschlitz an alle versendet.
Im nächsten Zeitschlitz, Nr. 5, sendet wieder Head C. Diesmal schickt er ein Poll-Paket mit den zuvor (in Slot 2) empfangenen Daten und fordert gleichzeitig Client B auf, ein Datenpaket zu versenden. In dem Antwortpaket gibt B dann an, ob er das Datenpaket der Vorrunde empfangen hat, und versendet seine eigenen Daten zur weiteren Auslieferung über den Cluster-Head.
Der sechste Zeitschlitz bleibt von den beiden Clustern ungenutzt, danach beginnt wieder Head A.
Anfänglich steht jedem Client in seinem Cluster ein reservierter Zeitschlitz pro Poll-Runde zu. Hat der Head nicht die Maximalanzahl an Clients, werden nach Abfrage der zugesicherten Runden alle Clients im Round-Robin-Verfahren befragt.
Benötigt ein Client für eine Übertragung höhere Bandbreite, so muss er zunächst bestimmen, in welchen seiner Cluster diese Übertragung gehen soll. Danach kann er sich mehrfach in die Poll-Liste des Heads eintragen lassen und dadurch mehrere Zeitschlitze bekommen. Mit der Zusicherung der Zeitschlitze ist auch die Garantie verbunden, dass die so gesendeten Daten an alle Stationen im Cluster ausgeliefert werden. Der effektive Anteil an der Netzwerk-Bandbreite entspricht dabei der Anzahl der reservierten Slots dividiert durch die Anzahl der Slots pro Runde.
Zum Reservieren wartet ein Client das nächste Invite-Paket ab und verschickt eine Benachrichtigung an den Head, dass er eine höhere Slot-Anzahl benötigt. Nach einer Runde kann der Client dann im nächsten Invite-Paket sehen, ob sein Wunsch berücksichtigt wurde und er entsprechend oft eingetragen ist. Ist das der Fall, so wird er in den Runden darauf häufiger befragt und kann mehr Datenpakete versenden.
Die Anzahl der für einen Client verfügbaren Slots ist durch die maximale Anzahl der Clients pro Cluster minus der bereits eingebuchten Clients begrenzt. Können sich bis zu 16 Clients zu einem Head verbinden und sind schon 5 Clients eingebucht, so kann einer dieser Clients (oder der Head) bis zu 11 Slots nutzen (fünf sind für die Clients und einer für den Head reserviert, zusätzlich dazu kann jeder Teilnehmer die zehn freien Zeitschlitze reservieren).
Die Reservierung der Zeitschlitze erfolgt asynchron. Die Anwendung muss dem Clustering-Modul mitteilen, wie viele Slots sie in einem bestimmten Cluster benötigt. Daraufhin versucht der Knoten, die entsprechende Anzahl an Slots beim Head zu reservieren, und informiert die Anwendung über den Erfolg oder Misserfolg.
Die Entwicklung eines Kommunikationsprotokolls wird vom Testen der Implementierung begleitet. Die Überprüfung auf einem realen Netzwerk bringt dabei einen hohen Aufwand mit sich, da die aktuelle Softwareversion für alle Rechner zu übersetzen und auf sie zu verteilen ist, wonach die Ergebnisse zur Auswertung wieder eingesammelt und synchronisiert werden müssen. Außerdem ist es schwierig, bei jedem Testlauf identische Ausgangsbedingungen zu erzeugen, um Änderungen im Protokollverhalten besser analysieren zu können.
Um diese Probleme zu umgehen, kann statt einem realen mobilen Netzwerk auch auf eine Simulation eines solchen zurückgegriffen werden. Dabei hat sich der Network Simulator ns-2 [NS2] als solides Werkzeug für die realitätsnahe Simulation drahtloser Netze herausgestellt. Ns-2 ist ein diskreter ereignisbasierter Simulator, der in C++ geschrieben wurde und sehr flexibel gesteuert und erweitert werden kann.
Über TCL-Scripte erlaubt er neben der Konfiguration der Anzahl der Knoten auch Einstellungen der Sende-Reichweite, der Signalverluste und anderer Parameter. Außerdem ist es damit möglich, den Ablauf der Simulation genau zu beeinflussen und auf einzelnen Knoten zu bestimmten Zeitpunkten Ereignisse auszulösen.
Des Weiteren generiert ns-2 bei der Ausführung Ergebnisdateien (trace files), die sich im Anschluss an die Simulation mit nam (dem Network Animator[NAM], Abbildung 2.3) visualisieren lassen. Dabei ist es möglich, eigene Informationen in die Visualisierung einzubinden.
Allerdings besitzt ns-2 eine andere Programmierschnittstelle als die üblichen Netzwerkbetriebssysteme, so dass eine direkte Migration schwierig ist.
Um dennoch eine gemeinsame Basis für Simulation und Feldtest zu haben, kann auf die Generic Event-based API (GEA) [HM05] als Abstraktionsbibliothek zurückgegriffen werden. Diese Zwischenschicht wurde mit dem Ziel eingeführt, bei der Entwicklung von Netzwerkprotokollen die selbe Code-Basis sowohl in der Simulation als auch bei realen Experimenten einsetzen zu können. Dazu kapselt sie alle Netzwerkfunktionen gegenüber dem Protokoll und seinen Anwendungen ab und setzt diese auf die verwendete Systemschnittstelle um (Abb. 2.4).
GEA-Anwendungen können ohne Quellcode-Änderung auf den von GEA unterstützten Plattformen eingesetzt werden. Aktuell sind das der Netzwerksimulator ns-2 und Betriebssysteme, die die POSIX[COR]-Netzwerkschnittstelle anbieten. GEA-Anwendungen für diese beiden Plattformen sind sogar binärkompatibel.
Das eigene Protokoll wird dabei in eine dynamisch ladbare Bibliothek gebunden, die zur Laufzeit von einem entsprechenden GEA-Backend geladen wird. Dabei ist es auch möglich, mehrere Protokollteile in unterschiedliche Bibliotheken zu binden, um diese zu unterschiedlichen Zeitpunkten oder nur auf einem Teil der Netzwerkknoten zu laden.
Analog wird auch mit der Anwendung verfahren, die das Protokoll verwendet. Diese muss lediglich nach dem Protokollmodul geladen werden.
GEA arbeitet ereignisorientiert: Es bietet eine Möglichkeit, zeitgesteuerte oder von externen Quellen (repräsentiert über Socket- oder Datei-Handles) ausgelöste Ereignisse zu bearbeiten, indem man dafür Rückruffunktionen definiert. Diese Rückruffunktionen werden von einer zentralen Behandlungsroutine in GEA aufgerufen, sobald das entsprechende Ereignis vorliegt oder wenn die für das jeweilige Ereignis gesetzte maximale Wartezeit überschritten ist.
Die API bietet einen für die Implementierung eines Netzwerkprotokolls erforderlichen Mindestsatz an Methoden. Dazu gehören neben dem Versenden und Empfangen von Netzwerknachrichten auch Funktionen zum Bestimmen von Zeiten und Zeitdifferenzen, sowie die Möglichkeit, Rückruffunktionen für eigene Ereignisse und für bestimmte Zeitpunkte zu setzen.
Zusätzlich bietet GEA eine Möglichkeit, zwischen einzelnen Modulen Objekt-Referenzen auszutauschen. Dazu dient das Object Repository, eine Ablage, in der unterschiedliche Module ihre Objekte hinterlegen können. Diese Objekte können dann von anderen Modulen über ihren Namen und ihren Typen aus dem Object Repository bezogen werden.
Auf der POSIX-Schicht werden die Nachrichten als UDP-Pakete versendet. Obwohl die Verwendung von Paketen der MAC-Schicht für das Implementieren von Routing-Protokollen geeigneter wäre, erfordert die direkte Nutzung der Netzwerkkarte auf Unix-Systemen zusätzliche Benutzerrechte und ist stark plattformabhängig. UDP dagegen bietet auch die notwendigen Funktionen (Versand von Punkt-Zu-Punkt- und Broadcast-Nachrichten) und ist von den Socket-Funktionen der POSIX-API abgedeckt. Der Mehraufwand für die Verarbeitung der UDP-Pakete durch das Betriebssystem ist gleichzeitig so gering, dass er gegenüber dem eigentlichen Protokoll nicht ins Gewicht fällt.
Die Kombination aus ns-2 und GEA bietet damit ein flexibles Gerüst für die Entwicklung und Evaluierung eines Netzwerkprotokolls und erlaubt die einfache Migration von der Simulation auf echte Systeme.
![\includegraphics[width=0.8\textwidth]{02_cluster}](thesis-glukas-img5.png)
![\includegraphics[width=0.8\textwidth]{02_clusterzeit}](thesis-glukas-img8.png)
![\includegraphics[width=0.8\textwidth]{02_geastrukt}](thesis-glukas-img9.png)