Um für Verbindungen innerhalb des mobilen Netzwerks Garantien für Bandbreite und Zuverlässigkeit bieten zu können, müssen alle beteiligten Knoten, also die Gateways auf der Route, ihr Einverständnis dazu erteilen. Dazu müssen sie über die Anforderungen an die Verbindung informiert werden und diese bestätigen können. Dies erfordert einen Multi-Hop-Kommunikationskanal ohne Dienstgütegarantien.
Um einen solchen Kanal anzubieten, müssen die Knoten zum einen beim Versand von Nachrichten kooperieren, also nicht nur die eigenen Pakete versenden, sondern auch die Pakete anderer Stationen weiterleiten. Zum anderen benötigen sie ein Wissen über die Netzwerkstruktur, anhand dessen sie feststellen, ob sie für die Weiterleitung der Pakete überhaupt zuständig sind, und in welche Richtung (bzw. in welchen Cluster) sie die Pakete weiterzuleiten haben.
Dazu wurde im Rahmen dieser Arbeit ein Weltmodell-Propagationsverfahren und ein darauf aufbauendes Best-Effort-Routing-Protokoll entwickelt, welche in diesem Kapitel vorgestellt werden.
Die Auswahl des Routing-Protokolls beruht auf mehreren Kriterien, die es möglichst gut zu erfüllen gilt. Zunächst erfordert die Aufgabenstellung, dass das Protokoll auf dem Reliable-Clustering-Modell mit festen Zeitschlitzen aufsetzt. Da keines der in Kapitel 2 vorgestellten Protokolle darauf ausgelegt ist, muss eines davon angepasst oder ein eigenes entwickelt werden. Beim Präzisieren der Auswahl hilft das Klassifizierungsschema für Routing-Protokolle aus Abschnitt 2.2.1.
Wesentliche Anforderungen an das Routing-Protokoll sind die schnelle Zustellung von Datenpaketen an alle möglichen Ziele im Netzwerk und die Möglichkeit, viele Verbindungen zwischen unterschiedlichen Knoten zu führen.
Aus diesen Gründen sind reaktive Protokolle, die vor einer Datenübertragung erst den Pfad suchen müssen und damit höhere Aufbaulatenzen und starke Netzwerklast bei vielen unterschiedlichen Verbindungen mit sich bringen, nicht sinnvoll.
Hybride Protokolle erlauben den schnellen Pfadaufbau zu Knoten innerhalb der eigenen Gruppe bzw. Zone, aber nicht zu allen Stationen im Netzwerk. Daher sind auch sie nicht geeignet.
Ein proaktives Routing-Protokoll dagegen führt auf jedem Knoten die nötigen Informationen, um schnell an beliebige andere Knoten Daten zu verschicken, so dass die Wahl darauf fällt. Die höhere Belastung des Netzwerks durch die Propagation der Routing-Daten fällt dagegen aus zwei Gründen nicht ins Gewicht: Zum einen finden, bedingt durch das Cluster-Schema, bereits permanent Datenübertragungen statt, die man ohne Beeinträchtigung des Betriebs für die Propagation nutzen kann. Zum anderen ist die Netzwerklast bei einem reaktiven Verfahren höher, wenn dieses immer viele Verbindungen durch das Netz aufzubauen hat.
Ein Routing-Protokoll, welches nur Ziel-Vektoren (distance-vector; Abstand und Gateway zu jedem Ziel-Knoten) austauscht, ist bandbreitenschonener als ein Verfahren, das auf vollständigen Nachbarschaftsbeziehungen (link-state) beruht.
Allerdings haben ziel-basierte Verfahren nicht nur mit dem Count-To-Infinity-Problem zu kämpfen, sondern erlauben es auch nicht, unterschiedliche Pfade zu einem bestimmten Ziel zu bestimmen.
Da die Verwendung alternativer Pfade für das später darauf aufsetzende QoS-Routing relevant ist, kommen also nur Link-State-Verfahren in Frage.
Das Cluster-Schema gibt auf den ersten Blick bereits eine Struktur für das Routing-Protokoll vor. Allerdings sind alle Knoten gleichberechtigt, was ihre Sendemöglichkeiten angeht. Da alle Clients von der Clustering-Schicht nur über die ihnen benachbarten Heads, nicht aber über die anderen Clients in ihren Clustern, und alle Heads jeweils nur über ihre Clients informiert werden, kann hier auch eine flache Sichtweise auf die Netzwerktopologie angewandt werden. So muss lediglich beachtet werden, dass jeder zweite Knoten auf einem Pfad ein Gateway ist, während die anderen in ihrer Funktion als Cluster-Head nicht aktiv am Routing teilnehmen.
Auf diese Weise lässt sich mit einer flachen Weltmodell-Struktur ohne Beeinflussung der Arbeitsweise Datenverkehr einsparen (da weniger Struktur-Informationen zu übertragen sind) und das Routing-Konzept kann leichter auf andere, nicht clusterbasierte, MAC-Schichten portiert werden.
Aus den in Kapitel 2 vorgestellten Protokollen sind nur OLSR und FSR proaktiv und tauschen Link-State-Daten aus. Da OLSR jedoch seine eigene Struktur verwendet, die in Kombination mit der Cluster-Struktur die Komplexität deutlich steigern würde, und weil die Periodizität der Updates eigenen Mechanismen unterliegt und nicht so flexibel geregelt werden kann wie bei FSR, wurde Fisheye State Routing als Grundlage für die weitere Arbeit herangezogen.
Ein weiteres Argument dafür ist, dass FSR sowohl mit steigender Knotenanzahl als auch mit hoher Mobilität gut skaliert.
Da die bestehenden Implementierungen von FSR entweder auf einen anderen Simulator ausgelegt sind ([Bec]) oder Linux erfordern ([HOR]) und für die Kooperation mit GEA und dem Clustering-Schema stark abgewandelt werden müssten, wurde das Verfahren statt dessen ausgehend von der Entwicklungsumgebung und den aus dem Clustering resultierenden Anforderungen neu implementiert.
Die resultierende Implementierung sorgt dafür, dass die Informationen über die unmittelbare Nachbarschaft sehr präzise sind, während man von weiter entfernten Knoten eine ältere Topologie-Sicht hat, die zwar nicht die letzten Änderungen der Konnektivität berücksichtigt, dafür aber immer noch genügt, um zu bestimmen, welches Gateway für welches Ziel zuständig ist. Da die Gateways näher zum Ziel auch immer präzisere Informationen über die verbleibende Strecke haben, können sie das Paket zunehmend genauer zum Empfänger navigieren.
Abweichend vom originalen FSR-Entwurf wurde die Weltmodell-Propagation dem Zeitschema des Clustering-Protokolls angepasst: Da jeder Knoten regelmäßig von einem seiner Heads nach einem zu versendenden Datenpaket gefragt wird und auch eins versenden muss, aber nicht immer Daten dafür bereithält, werden diese ansonsten ungenutzten Zeitschlitze für den Versand von Topologiedaten eingesetzt.
Auf diese Weise wird das Medium optimal ausgelastet und die Aktualität des Weltmodells ist gut, ohne dass dafür normaler Datenverkehr zurückstehen muss. Zudem braucht die Routing-Schicht keine eigenen periodischen Updates mehr zu generieren, da ihr das vom MAC-Protokoll abgenommen wird.
Jeder Knoten ist zunächst nur in der Lage, seine unmittelbare Nachbarschaft zu sehen (Abb. 3.1, Schritt 1, unterlegte Fläche). Um mit weiter entfernten Knoten kommunizieren zu können, muss er Informationen über die Pfade zu diesen Knoten beziehen und entsprechend auch seine eigenen Informationen weitergeben, um erreichbar zu sein. All diese Informationen fasst ein Knoten dann in seinem lokalen Weltmodell - einer möglichst getreuen Abbildung der Netzwerkstruktur - zusammen und versendet Änderungen des Weltmodells an seine Nachbarn, die diese wiederum abspeichern und weitergeben. So erhält er erst ein Bild über die Umgebung seiner unmittelbaren Nachbarn (Schritt 2), dann über die Drei-Hop-Nachbarn (Schritt 3) und irgendwann schließlich über das gesamte Netzwerk (Schritt 4).
Bleibt das Netzwerk stabil, erhalten alle Stationen nach einer bestimmten Zeit ein konsistentes Bild über die gesamte Topologie. Ändern sich die Verbindungen eines Knotens, so gibt er die neuen Informationen an seine direkten Nachbarn weiter, die diese nach und nach durch das gesamte Netzwerk propagieren, bis wieder alle ein konsistentes Abbild haben. Bewegen sich viele Knoten, so erreichen die aktuellen Informationen die unmittelbare Nachbarschaft. Die Topologiedaten werden nicht mehr zeitnah an weiter entfernte Knoten übertragen, was jedoch nach dem Fish-Eye-Prinzip unproblematisch ist.
Mit Hilfe des so kommunizierten Weltmodells kann ein Knoten Pfade zu allen anderen Stationen im Netzwerk bestimmen. Auf diesen Pfaden können dann die eigenen Anwendungen Nachrichten versenden. Zusätzlich wirkt jeder Knoten auch als Gateway: Empfängt er Pakete von seinen Nachbarn, die weitergeleitet werden sollen, so muss er dies entsprechend den berechneten Pfaden tun.
Um Routing zwischen Clustern zu ermöglichen, müssen mehrere Module miteinander interagieren (Abb. 3.2). Zum einen muss das Weltmodell aktuell gehalten werden. Dies geschieht, indem das Weltmodell-Modul Daten über die eigene Nachbarschaft von der MAC-Schicht bezieht und diese Informationen an die Nachbarn sendet, sowie solche Informationen von den Nachbarn empfängt und an andere Nachbarn weiterleitet.
Zum anderen muss der Knoten auch eine Aufgabe als Gateway wahrnehmen. Dazu muss er empfangene Pakete untersuchen, überprüfen ob er für die Weiterleitung zuständig ist und gegebenenfalls den weiteren Pfad berechnen und das Paket entsprechend verschicken. Analog muss er bei Paketen vorgehen, die von der lokal laufenden Anwendung verschickt werden oder an sie gerichtet sind. Die beiden Teilmodule ,,Weltmodell'' und ,,Multi-Hop-Routing'' sollen im Folgenden detailliert vorgestellt werden.
Das Weltmodell ist in Unterkomponenten aufgeteilt (Abb. 3.3). Eine zentrale Stelle nimmt dabei der Topologiespeicher ein, in dem alle Informationen über die Netzwerkstruktur abgelegt sind. Diesen Speicher benutzt der Pfadsucher, wenn er von der Routing-Schicht damit beauftragt wird, das Gateway für einen bestimmten Knoten ausfindig zu machen.
Der Speicher wird zum einen dadurch gefüllt, dass die MAC-Schicht über eine Überwachungsschnittstelle Informationen über die eigenen Nachbarn liefert. Zum anderen wertet das Weltmodell ankommende Datenpakete mit den Nachbarschaftsbeziehungen anderer Knoten aus.
Wenn die Station von ihrem Head mit einem Poll-Paket abgefragt wird und die Anwendung keine Daten zu versenden hat, so füllt das Weltmodell aus seinem Speicher ein Datenpaket mit Topologiedaten, welches dann an die Nachbarn propagiert wird.
Um Routen berechnen zu können, muss jeder Knoten die Topologie des gesamten Netzwerks kennen. Da ein einzelner Knoten jedoch keine fremden Verbindungen einsehen kann, muss er sich darauf verlassen, die Topologiedaten anderer Knoten über seine Nachbarn zu beziehen - und im Gegenzug dazu seine eigenen Informationen an die restlichen Teilnehmer weitergeben.
Da solche Daten auf unterschiedlich langen Wegen und durch die passive Ausbreitungsart mit starken Verzögerungen zu einem Knoten gelangen können, muss dieser entscheiden, ob er aktuellere Informationen erhalten hat, als er schon besitzt. Dies wird dadurch realisiert, dass jeder Knoten eine Sequenznummer für seine Nachbarschaftsbeziehungen führt und diese bei jeder Änderung seiner direkten Nachbarschaft erhöht. Diese Sequenznummer wird dann zusammen mit der aktuellen Liste seiner Nachbarn übertragen. Ein empfangender Knoten kann daran sehen, ob sich etwas geändert hat, und ob die Information, die er erhalten hat, aktuell ist.
Obwohl die Links zwischen zwei Knoten immer ungerichtet sind, werden sie im Weltmodell als zwei gerichtete Verbindungen abgebildet (Abb. 3.4, die Zahlen rechts unten in jedem Knoten sind die jeweiligen Topologie-Sequenznummern). Diese Herangehensweise erlaubt eine schnellere Pfadsuche im abgespeicherten Graphen (man erkennt bei jedem Knoten unmittelbar, zu wem dieser Verbindungen hat).
Des Weiteren umgeht man damit das Problem, dass eine Verbindung immer zwischen zwei Knoten besteht, die unterschiedliche Sequenznummern führen. Würden Verbindungen nur als ungerichtet übermittelt werden, so könnten Inkonsistenzen im Graphen auftreten, wenn Knoten A angibt, eine Verbindung zu Knoten B zu haben, während die letzte Information von Knoten B keine Verbindung zu A aufweist. Da die Sequenznummern von A und B nicht korrelieren, kann ein Außenstehender nicht beurteilen, welche der beiden Aussagen aktueller ist.
Wird eine Verbindung dagegen als ein Paar gerichteter Strecken abgelegt, so stellt die Information, dass A mit B verbunden ist, aber B nicht mit A, keine Verletzung des Modells dar. Obwohl dieser Zustand im realen Netz nicht existiert, wird er im Topologiespeicher so abgelegt, bis es von A bzw. B aktualisierte Informationen gibt und die Strecke wieder konsistent ist.
Diese Herangehensweise erhöht zwar leicht den Netzwerk-Overhead, sie sorgt aber ansonsten nicht für eine Verschlechterung des Routing-Verhaltens - wird das Netz partitioniert, so stellen die Knoten auf der einen Seite fest, dass sie keine Verbindung zur anderen haben. Auch wenn in ihrem Weltmodell verzeichnet ist, dass die andere Seite eine Verbindung zu ihnen hat, ist das für das Routing nicht relevant (Abb. 3.5: Knoten 6 versucht erfolglos eine Verbindung zu Knoten 3 aufzubauen). Wenn die neuen Topologiedaten des isolierten Knotens dann das restliche Netz erreichen, verschwindet auch der veraltete Link in die Gegenrichtung.
Das Weltmodell ist ein gerichteter Graph, dessen Knoten die Stationen sind und dessen Kanten direkte Verbindungen zwischen Stationen darstellen. Es wird in Form einer Adjazenzliste abgelegt, wobei es hilfreich ist, die Datenstruktur auf wahlfreien Zugriff über Knotennummern zu optimieren. Diese Zugriffsart wird für die Pfadsuche und für Aktualisierungen benötigt wird und ist daher performancekritisch.
Zu jedem Knoten wird im Speicher die zuletzt empfangene Liste seiner Nachbarn und die dazugehörige Sequenz-Nummer abgelegt - diese beiden Informationen bilden eine Einheit und werden immer zusammen ausgesendet oder aktualisiert.
Ist eine solche Struktur zur Speicherung der Knoten einmal vorhanden, kann sie auch für die Zwischenspeicherung der lokal berechneten Routen benutzt werden. Dies hat den Vorteil, dass Pfade nicht für jede Suche neu berechnet werden müssen, sondern erst dann, wenn sich das Weltmodell geändert hat.
Als Suchverfahren wird der Algorithmus von Dijkstra[Dij59] verwendet,
da im Modell keine negativen Kantengewichte auftreten und die
Dijkstra-Laufzeit bei ![]() Knoten und
Knoten und ![]() Kanten mit
Kanten mit
![]() gut ist.
gut ist.
Aus der Pfad-Berechnung ergeben sich zu jedem Knoten mehrere Informationen, die im Weltmodell abgespeichert werden. Zunächst einmal ist das der Abstand von der eigenen Station zum Zielknoten, gemessen in Hops. Des Weiteren gehört dazu der Next-Hop, also der eigene Nachbar, der dem Ziel am nächsten liegt. Zuletzt enthält die Liste noch den Vorgänger des Zielknotens. Dieser wird abgelegt, um ausgehend vom Ziel den Pfad rekonstruieren zu können.
|
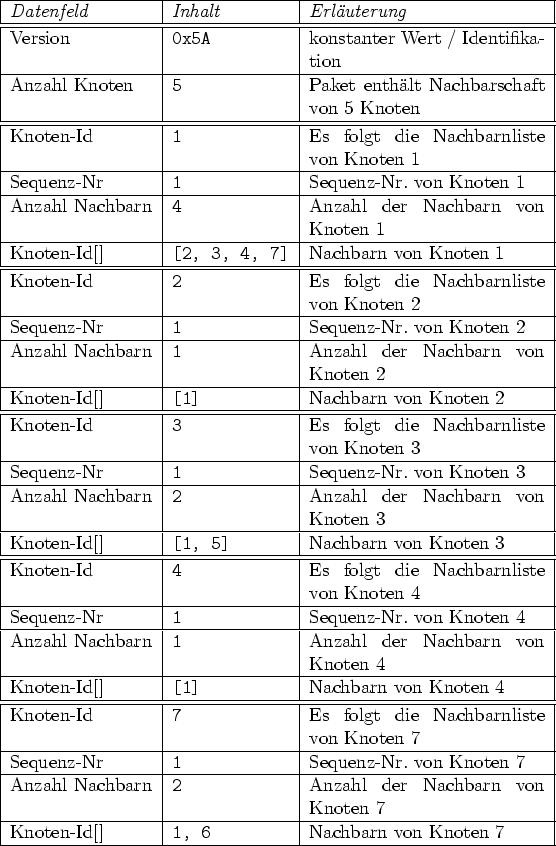
In Tabelle 3.1 ist das Weltmodell von Knoten 6 aus Abb.
3.5 dargestellt. Der Knoten führt auch die Informationen über
sich selbst im Weltmodell. Von diesen ausgehend berechnet er dann nach und
nach den Routing-Cache. Die Berechnung ergibt, dass er alle anderen Knoten
(bis auf 3, der gar nicht erreichbar ist) über seinen Nachbarn 7 als Gateway
erreichen kann. Wird der komplette Pfad, z.B. zu Knoten 4 gesucht, so muss
dieser zurückverfolgt werden: Der Vorgänger von 4 ist 1, der Vorgänger von 1
ist 7, und davor kommt 6, umgedreht ist der korrekte Pfad also:
![]() .
.
Da jeder Knoten durch seine Cluster-Zugehörigkeit seine direkten Nachbarn kennt, kann er diese Informationen als Grundlage für den Aufbau seines Weltmodells heranziehen. Auf Anforderung der MAC-Schicht generiert er dann ein Datenpaket, welches mit seiner lokalen Sicht gefüllt ist. Dabei werden bevorzugt neue Informationen über den eigenen bzw. über näher gelegene Knoten eingebettet, und zu einem Knoten seine Sequenznummer und die komplette Liste seiner Nachbarn abgelegt.
In einem Datenpaket befinden sich die Nachbarschaftsbeziehungen von so vielen Knoten, wie es der Speicherplatz zulässt. Da ab einer bestimmten Netzwerkgröße nicht mehr alle Knoten in einem Datenpaket untergebracht werden können, muss ausgewählt werden, welche Daten zu versenden sind und welche nicht.
Dazu werden zwei Warteschlangen geführt, eine für aktualisierte Nachbarschaftsdaten und eine für die, die seit ihrem letzten Versenden nicht verändert wurden. Jedes Mal, wenn der Knoten neue Daten von einer anderen Station empfängt, wird diese Station aus der zweiten in die erste Warteschlange übertragen, sofern sie nicht bereits darin steht.
Zum Versenden wird zunächst überprüft, ob sich die eigene Nachbarschaft geändert hat. Falls ja, wird die eigene Adjazenzliste als erstes in das Paket geschrieben.
Danach wird die Warteschlange mit aktualisierten Daten abgearbeitet und die entsprechenden Knoten-Nachbarn in das Paket geschrieben, bis entweder die Warteschlange leer oder das Paket voll ist. Dabei wandern alle Knoten, die im Paket erfasst wurden, an das Ende der zweiten Warteschlange.
Ist im Paket noch Platz, so wird daraufhin die zweite Warteschlange abgearbeitet, bis entweder das gesamte Weltmodell erfasst ist (was bei kleinen Netzen der Fall ist), oder bis das Datenpaket keine Knoten mehr aufnehmen kann.
Konnten keine Datenpakete aus der unprivilegierten Warteschlange aufgenommen werden, so wird das erste Element daraus an die ,,Geändert''-Warteschlange angehängt, um ein ,,Verhungern'' der weniger wichtigen Daten zu verhindern.
Die clusterübergreifende Übertragung von Daten erfordert die Kooperation der Teilnehmer im mobilen Netzwerk. Dazu muss jeder Knoten mehrere Komponenten bereitstellen, die im Folgenden vorgestellt werden und deren Zusammenspiel in Abbildung 3.6 dargestellt ist.
Will ein Knoten ein Datenpaket an einen beliebigen anderen Knoten im gesamten Netz übertragen, so muss er mit Hilfe des Weltmodells die Route zum Empfänger bestimmen. Für den Versand wird dabei der Gateway-Knoten aus den eigenen Clustern ermittelt, der dem Ziel am nächsten ist. Das Datenpaket wird in eine Warteschlange gesetzt, um bei der nächsten Anfrage des Ziel-Heads versendet zu werden.
Um die Zwischenspeicherung zu realisieren ist es zunächst naheliegend, eine Paketwarteschlange pro Cluster einsetzen. Da sich jedoch die Topologie ändern kann, während ein Datenpaket in der Warteschlange verbleibt, ist es besser, die Route für alle wartenden Pakete anhand der Ziel-Adressen neu zu bestimmen, wenn diese tatsächlich benötigt wird, also wenn der Knoten aufgefordert wird, ein Paket zu versenden.
Deswegen wird nur eine zentrale Warteschlange eingesetzt, die bei jeder Paketanforderung untersucht wird. Dabei wird für jedes Paket, das sich dort befindet, der nächste Gateway-Knoten und der Cluster, in dem sich dieses Gateway befindet, bestimmt. Stimmt der ermittelte Cluster mit dem überein, aus dem die Paket-Anfrage stammt, so wird das Paket ausgeliefert und aus der Warteschlange gelöscht.
Zusätzlich muss aber auch dafür gesorgt werden, dass Datenpakete, für die keine Route mehr existiert, nicht ewig in der Warteschlange verbleiben. Da nicht vorhergesagt werden kann, wann der Pfad zu einem Knoten wieder verfügbar ist und ob man das Ziel überhaupt erreichen können wird, werden alle solchen Pakete gelöscht.
Die Warteschlange wird sowohl für von der Anwendung erzeugte Pakete als auch für die Datagramme verwendet, die der Knoten von seinen Nachbarn empfängt und für deren Weiterleitung er zuständig ist. Die Pakete werden dort in Empfangsreihenfolge eingetragen und nach einem bei den ältesten Paketen beginnenden Auswahlverfahren wieder entfernt.
Innerhalb eines Clusters wird ein Datenpaket zuverlässig an alle Stationen ausgeliefert. Obwohl für das Multi-Hop-Routing nur die Auslieferung an das Gateway relevant ist, sieht das Clustering-Schema bisher keine Möglichkeit für die Einschränkung der Empfängerliste vor.
Da ein Datenpaket von allen Knoten im Cluster empfangen wird, müssen diese zunächst feststellen, ob sie für dessen Weiterleitung zuständig sind. Dazu muss im Paket-Header neben dem Empfänger auch das nächste Gateway vermerkt werden. Erhält ein Knoten ein Paket, in dem eine andere Station als Gateway eingetragen ist, so wird das Paket verworfen. Erkennt der Knoten, dass er zuständig ist, so überprüft er das Ziel-Feld im Paket. Ist das Paket an ihn gerichtet, reicht er es an die Anwendung weiter. Wird ein anderer Knoten adressiert, so wird das Paket an die Warteschlange angehängt.
Wird ein Knoten von einem seiner Cluster-Heads aufgefordert, Daten zu verschicken, so erhält das Multi-Hop-Modul eine Anfrage von der MAC-Schicht und überprüft seine Paket-Warteschlange.
Ist die Warteschlange leer, signalisiert die Multi-Hop-Schicht das entsprechend und das Paket wird stattdessen vom Weltmodell mit Topologie-Informationen gefüllt.
Enthält die Warteschlange Datenpakete, so wird das Weltmodell zunächst aufgefordert, alle Pfade im Routing-Zwischenspeicher neu zu berechnen. Dies geschieht nur, wenn seit der letzten Berechnung Änderungen an der Topologie stattgefunden haben.
Liegen dann aktuelle Routen vor, so geht der Paket-Versender die Warteschlange von vorn durch und holt zu jedem Paket den Ziel-Cluster aus dem Routing-Speicher des Weltmodells. Entspricht der Ziel-Cluster für das Paket dem Cluster, an den das nächste Paket gehen soll, so wird das Gateway aus dem Routing-Cache in das Paket eingetragen, und es der MAC-Schicht zum Versand übergeben.
Da das Weltmodell eine flache Struktur hat, unterscheidet es nicht zwischen Heads und Clients. Um also den Ziel-Cluster und das nächste Gateway zu bestimmen, muss der Zustand des eigenen Knotens in Betracht gezogen werden.
Ist der eigene Knoten ein Head, so werden alle Datenpakete in den eigenen Cluster verschickt. Der Next-Hop des Weltmodells ist dabei das Gateway, das ins Paket einzutragen ist, da ein Head immer nur mit Clients verbunden sein kann, und nur Clients eine Rolle als Gateway wahrnehmen können.
Ist der Knoten dagegen ein Client, so sind seine unmittelbaren Nachbarn Heads, und der Next-Hop aus dem Weltmodell entspricht dem Cluster, in den das Paket verschickt werden muss. Das Gateway im Ziel-Cluster ist dann aus Sicht des Weltmodells der übernächste Hop, auf den man aber nicht unmittelbaren Zugriff hat. Aus diesem Grund wurde der Routing-Speicher des Weltmodells um ein weiteres Feld für den übernächsten Hop erweitert, um zusätzlichen Berechnungsaufwand für den Knoten zu ersparen.
Entsprechend vergleicht der Client den Next-Hop für den Paket-Empfänger mit
der Cluster-Id, aus der die Poll-Anfrage kommt. Stimmen diese überein, so
wird der übernächste Hop aus dem Weltmodell als Gateway in das Paket
eingetragen und das Paket an die MAC-Schicht gegeben. Auch hier ist durch die
Cluster-Struktur sichergestellt, dass der übernächste Knoten ein Client ist
und damit ein Gateway für das Paket sein kann (Client ![]() Head
Head
![]() Client).
Client).
Da jeder Knoten sein eigenes Weltmodell hat, kann es vorkommen, dass zwei Gateways der Meinung sind, der jeweils andere würde für ein bestimmtes Ziel zuständig sein. Da Source-Routing, die klassische Lösung für das Routing-Schleifen-Problem, nicht mit dem Fish-Eye-Prinzip kombinierbar ist, muss ein anderes Mittel gewählt werden. Für Best-Effort-Pakete wurde dabei eine TTL, bzw. ein Hop-Zähler, implementiert, der vom Sender auf einen bestimmten Wert gesetzt und von jedem Gateway dekrementiert wird. Erreicht die TTL den Wert 0, so wird das Paket stillschweigend verworfen.
Obwohl die Datenübertragung innerhalb jedes einzelnen Clusters zuverlässig abläuft (reliable broadcast an alle Stationen), können die Garantien nicht auf Verbindungen über Cluster-Grenzen hinweg ausgedehnt werden. Es gibt mehrere mögliche Ursachen dafür, dass ein Multi-Hop-Datenpaket sein Ziel nicht erreicht.
Zum einen ist es möglich, dass das Paket aufgrund von veralteten Topologiedaten verschickt wird und es keine reale Verbindung mehr zum Zielknoten gibt, weil dieser ausgefallen ist oder sich zu weit vom Kernnetz entfernt hat. In dem Fall wird das Paket auf der Station verworfen, deren Weltmodell keine Route mehr zum Empfänger hat.
Zum anderen kann es passieren, dass die TTL des Datenpakets vor Erreichen des Ziels auf 0 sinkt und das Paket deswegen verworfen wird. Die dafür möglichen Ursachen sind entweder eine Routing-Schleife oder ein Pfad, der länger ist als vom Sender berechnet. Die Wahl der TTL bildet dabei einen Kompromiss zwischen der Erreichbarkeit bei verlängerten Routen und der unnötigen Netzwerkbelastung bei Routing-Schleifen.
Im folgenden Abschnitt wird die Implementierung des Weltmodells und der Multi-Hop-Schicht detailliert vorgestellt und es wird auf ihre Komponenten und deren Zusammenarbeit miteinander, mit der Anwendung und mit der MAC-Schicht eingegangen.
Die Routing-Schicht arbeitet vollständig ereignisorientiert. Sie reagiert auf Ereignisse, die ihr von der unteren Schicht (MAC) oder von der höheren Schicht (Anwendung) signalisiert werden, und leitet diese Ereignisse bei Bedarf weiter.
Die MAC-Schicht stellt drei Ereignis-Typen bereit, für die sich die Routing-Schicht registrieren kann und die zum Empfang und Versand von Paketen dienen:
Um Ereignisse zwischen unterschiedlichen Modulen signalisieren zu können, wird eine einheitliche Schnittstelle benötigt. Eine solche Schnittstelle kann mit Hilfe von Rückruffunktionen implementiert werden. Dazu übergibt ein Modul, welches über ein Ereignis benachrichtigt werden will, einen Funktionszeiger und einen Datenzeiger an das ereignisauslösende Modul. Wenn das Ereignis stattfindet, wird die Funktion mit dem Datenzeiger und Informationen über das Ereignis als Parametern aufgerufen und kann darauf reagieren. Der Datenzeiger dient dabei der Rückruffunktion dazu, den Kontext der Registrierung zu rekonstruieren.
Da die Implementierung von Rückruffunktionen in Klassen bei den meisten C++-Compilern nicht sauber gelöst ist, werden statische Funktionen statt Methoden für Rückrufe eingesetzt und der Datenzeiger zum Abspeichern der Instanz verwendet, die den Rückruf registriert hat. Über diesen Zeiger können dann die Methoden des Objekts zur Ereignis-Behandlung aufgerufen werden.
Damit mehrere unterschiedliche Objekte auf ein Ereignis reagieren können, werden zur Ereignis-Mitteilung Hooks eingesetzt. Ein Hook ist ein Hilfsobjekt, das eine Liste der Rückruffunktionen zu einem Ereignis, sowie die den Funktionen zugehörigen Objektreferenzen führt. Wird das Ereignis ausgelöst, werden die Funktionen aus der Liste nacheinander ausgeführt, bis eine erfolgreiche Bearbeitung gemeldet wurde.
Es existieren zwei Hook-Typen - der erste ruft die Rückruffunktionen in der Reihenfolge auf, in der sie eingetragen wurden, der zweite richtet sich nach deren Priorität. Letzteres wird z.B. verwendet, um beim Versand von Paketen QoS vor BestEffort und BestEffort vor Topologiedaten zu stellen.
Abbildung 3.7 zeigt die Hooks, die zwischen der MAC-Schicht, der Multi-Hop-Middleware und deren Anwendung zum Tragen kommen. Sie werden zur Übergabe von Datenpaketen zur Auswertung und zum Befüllen mit Daten eingesetzt.
Jede Station im mobilen Ad-Hoc-Netz besitzt eine im Voraus festgelegte eindeutige Kennung, die in Datenfeldern des Typs NodeId abgespeichert wird. Der genaue Aufbau dieser Kennungen ist für das Routing-Protokoll nicht relevant, da sich aus ihnen wegen der Knotenmobilität keine Informationen zur Pfadsuche bestimmen lassen. In der Implementierung werden IP-Adressen als Knotennummern verwendet, die von GEA für den Versand und Empfang von UDP-Paketen eingesetzt werden. Die Rechneradressen müssen dafür im Voraus vergeben werden. Denkbar wäre auch die Verwendung von MAC-Adressen, da diese bereits eindeutig sind, dazu müsste lediglich der Datentyp von NodeId angepasst werden.
Damit Daten über das Netzwerk versendet werden können, müssen diese in Pakete verpackt werden. Dabei sind einige Besonderheiten zu beachten, wie z.B. die Byte-Reihenfolge von 16-Bit- und 32-Bit-Zahlen auf unterschiedlichen Plattformen. So speichern u.a. x86-Systeme das niederwertigste Byte eines größeren Datentyps zuerst (Little Endian), während Sparc- und PowerPC-Prozessoren mit dem höchstwertigen Byte beginnen (Big Endian). Im Netzwerk werden alle Datentypen als Big Endian übertragen, so dass CPU-abhängig Konvertierungen durchgeführt werden müssen. Manche Architekturen erlauben es außerdem nicht, 16- und 32-Bit-Felder an beliebigen Speicheradressen zu lesen und zu schreiben, sondern nur an Adressen, die durch die Feldgröße teilbar sind.
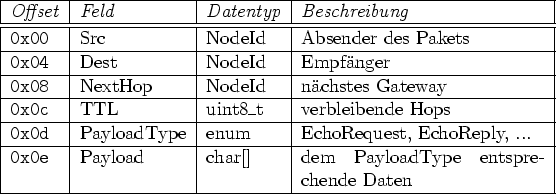
Damit die dafür nötige Kapselung möglichst transparent geschieht, wurden für unterschiedliche Pakettypen mehrere Klassen eingeführt. Dabei bildet BcPacket die Basisklasse, die von der MAC-Schicht verwendet und bei Ereignissen übergeben wird. Diese Klasse bildet alle für die clusterinterne Kommunikation nötigen Datenfelder auf ein Byte-Array ab. Dabei erfolgen Zugriffe auf die Felder über dafür vorgesehene Methoden, die eine Konvertierung in das Netzwerkformat automatisieren. Die BcPacket-Klasse gibt dem Nutzer die Möglichkeit, den Nutzdatenbereich direkt zu beschreiben und seine Größe festzulegen.
Der Inhalt des Nutzdatenbereichs hängt dabei vom Subtyp-Datenfeld ab (während das Typ-Datenfeld für die Cluster-Kommunikation reserviert ist).
Um weitere Variablen im Datenbereich ablegen zu können, wurde die darauf aufbauende (aber nicht davon abgeleitete) Klasse MultiHopPacket zur weiteren Kapselung eingeführt. Eine Instanz dieser Klasse wird auf einem BcPacket aufgesetzt und schreibt direkt in die Datenfelder, wobei hier wieder transparent die Konvertierung zwischen Rechner- und Netzwerk-Format stattfindet.
Ein MultiHopPacket sieht zusätzliche Datenfelder für die Cluster-übergreifende Kommunikation vor (Tabelle 3.2) und bietet der Anwendung wieder einen frei beschreibbaren Bereich, sowie Funktionen zum Ändern und Auslesen der Größe dieses Bereichs.
Um auf Topologieänderungen reagieren zu können, muss das Weltmodell darüber in Kenntnis gesetzt werden. Dazu sieht die MAC-Schicht eine Schnittstelle vor, die den Aufbau und Abbau von Links sowie Änderungen des eigenen Knoten-Zustands signalisiert. Diese Schnittstelle wird vom Weltmodell verwendet, um die Beziehungen des eigenen Knotens zu pflegen und an die Nachbarn weiterzusenden.
Realisiert wird diese Schnittstelle über die IntraMon-Klasse, von der man seine eigene Klasse ableiten kann. Instanziiert man die Klasse, so wird sie in einen Nachrichtenverteiler eingetragen, der Mitteilungen über die Änderung des Knotens von Head zu Client und zurück, sowie über hinzukommende und entfernte Heads bzw. Clients an entsprechende Klassenmethoden ausliefert.
Diese Schnittstelle wird vom Weltmodell verwendet, um die unmittelbare Nachbarschaft zu beobachten und Änderungen sofort zu übernehmen. Dabei wird die Nachbarliste komplett gelöscht und die Sequenz-Nummer inkrementiert, wenn der Knoten von Head zu Client oder umgekehrt wechselt. Bei hinzukommenden oder entfernten Nachbarn wird die interne Liste entsprechend angepasst und wiederum die Sequenznummer erhöht. Beides führt außerdem dazu, dass der eigene Eintrag eine erhöhte Sendepriorität bekommt, um bei der nächsten Weltmodell-Propagation an alle Nachbarn versendet zu werden.
Zusätzlich empfängt das Weltmodell über den promiscHook Pakete und wertet die darin evtl. vorhandenen Topologiedaten aus. Aus einem Topologie-Paket wird sequentiell jeder Knoten ausgelesen, seine Sequenz-Nummer mit der im eigenen Weltmodell verglichen, und falls die empfangende Nachbarschaftsliste aktueller ist, diese in das Weltmodell eingepflegt.
Das Weltmodell hat die Aufgabe, die Verbindungen zwischen allen Knoten abzuspeichern und bei Bedarf Pfade von der eigenen Station zu bestimmten Zielen zu berechnen. Da die Suche dabei auf jedem Gateway neu durchgeführt wird, um veraltete Weltmodell-Informationen zu kompensieren, ist nur das nächste Gateway und sein Cluster für das Weitersenden eines Pakets relevant. Diese werden im Weltmodell nach einer Routenberechnung zwischengespeichert und über die Funktionen getNextHop() und getClusterHead() bereitgestellt. Zuerst muss allerdings mit isRoutable() festgestellt werden, ob der Zielknoten überhaupt erreichbar ist.
Um den berechneten Pfad traversieren zu können, wurde des Weiteren getPrevHop() eingeführt. Diese Funktion liefert den vorletzten Knoten auf dem Pfad zu der übergebenen Id. Ruft man sie iterativ auf, so erhält man in umgekehrter Reihenfolge die Zwischenstationen zu einem beliebigen Ziel.
Das Weltmodell speichert neben einer Liste der bereits bekannten Knoten auch die Nachbarschaftsbeziehungen und Routing-Daten zu jedem dieser Knoten. Die Routing-Daten werden bei jedem neu ankommenden Topologiedaten-Paket als veraltet markiert und bei der nächsten Anforderung neu berechnet. Dadurch werden unnötige Berechnungen eingespart.
Knotenbezogene Informationen werden mit Hilfe der Klasse WorldModelElement geordnet. Eine Instanz davon speichert die von einem Knoten zuletzt gesehene Topologie-Sequenznummer, ein Feld seiner Nachbarschaft (vector<NodeId>) und die für diesen Knoten berechneten Routing-Daten.
Alle Elemente des Weltmodells werden in einem balancierten Baum
abgelegt, der die Einträge nach Knotennummern ordnet
(map<NodeId,WorldModelElement>). Auf diese Weise ist der wahlfreie
Zugriff auf Einträge mit einem Aufwand von
![]() möglich.
Dies ist besonders wichtig, da diese Operation sehr häufig benötigt wird.
möglich.
Dies ist besonders wichtig, da diese Operation sehr häufig benötigt wird.
Wird eine Station neu gestartet, so beginnt ihre Topologie-Sequenznummer wieder bei 1. Das Weltmodell der anderen Knoten enthält allerdings Informationen von der Station mit einer höheren Sequenznummer, so dass aktuellere Topologiedaten des neu gestarteten Knotens nicht übernommen werden.
Um dieses Problem einzudämmen, überprüft ein Knoten die von anderen verbreitete Sequenznummer für sein Weltmodell. Empfängt er einen Wert, der höher als sein eigener ist, geht er davon aus, dass er neu gestartet wurde. Um sein aktuelles Weltmodell an die Nachbarn propagieren zu können, ,,springt'' er mit seiner Sequenznummer über den empfangenen Wert.
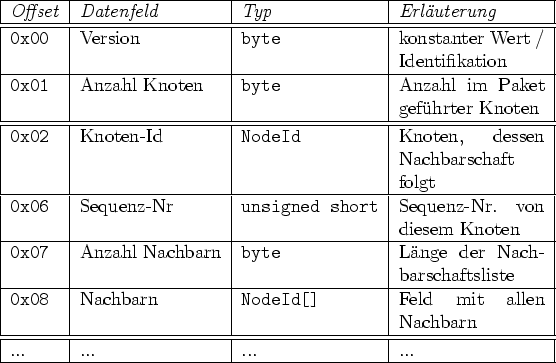
Wenn ein Knoten von einem seiner Cluster-Heads nach einem Paket gefragt wird, aber keine Daten zu versenden hat, generiert er ein Weltmodell-Paket (Format in Tabelle 3.3). Dabei werden bevorzugt neue bzw. aktualisierte Topologiedaten und danach die vorhandenen Bestandsdaten versendet.
Ein solches Datenpaket, am Beispiel von Knoten 1 in Abbildung 3.8, ist in Tabelle 3.4 aufgeschlüsselt. Dabei hat der Knoten bereits Informationen von allen unmittelbaren Nachbarn erhalten, allerdings nicht von den weiter entfernten Knoten, und verschickt sein komplettes Weltbild, welches noch in einem einzelnen Daten-Paket Platz findet.
Gegenüber der Anwendung exportiert die Routing-Schicht drei Callbacks. Neben dem von unten getriggerten Empfang und Versand von Multi-Hop-Paketen (ein Promiscuous Mode ist zwar möglich, wurde aber nicht implementiert) existiert noch ein Hook, der von der Anwendung aufgerufen werden kann, um ein Paket in die Sendewarteschlange einzureihen. Dies ist notwendig, damit sowohl synchron als auch asynchron Pakete versendet werden können, und kann z.B. für die Beantwortung von Ping-Paketen eingesetzt werden.
Es wurde eine Test-Anwendung implementiert, die in regelmäßigen Zeitabständen Ping-Pakete an einen vorgegebenen anderen Knoten im Netz verschickt. Die Datenpakete enthalten dabei einen Zählerwert und die lokale Zeit, zu der sie versendet wurden.
Empfängt die Anwendung ein solches Ping-Paket, so erzeugt sie ein Antwortpaket, das Pong, welches eine Kopie der Daten aus der Anfrage enthält und an den Absender des Ping-Pakets gerichtet ist.
Wenn die Antwort beim Absender ankommt, so kann dieser aus dem Zeitstempel im Datenpaket und der aktuellen Uhrzeit die Laufzeit für beide Richtungen ermitteln und diese ausgeben.
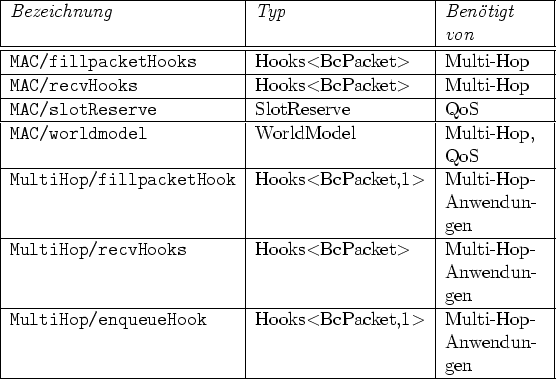
Die MAC-Schicht, das Best-Effort-Routing und die Test-Anwendung bilden eigene Module, die zur Laufzeit als dynamische Bibliotheken nachgeladen werden können. Dabei erzeugt jedes Modul beim Laden eine Instanz der eigenen Klasse. Damit die Module auch untereinander kommunizieren können, wird das Object Repository von GEA eingesetzt, das es erlaubt, unter einem bestimmten Namen ein Objekt und den dazugehörigen Typ abzuspeichern.
Das Object Repository wird für die in Tabelle 3.5 aufgezählten Objekte verwendet. Der Präfix in der Bezeichnung dient dabei der Unterscheidung zwischen den von der MAC-Schicht exportierten Objekten und denen aus der Multi-Hop-Routing-Schicht.
![\includegraphics[width=\textwidth]{03_nachbarschaft}](thesis-glukas-img10.png)
![\includegraphics[width=0.8\textwidth]{03_konzept}](thesis-glukas-img11.png)
![\includegraphics[width=0.8\textwidth]{03_konzeptwm}](thesis-glukas-img12.png)
![\includegraphics[width=0.8\textwidth]{03_bidilink}](thesis-glukas-img13.png)
![\includegraphics[width=0.8\textwidth]{03_bidipfad}](thesis-glukas-img14.png)
![\includegraphics[width=0.8\textwidth]{03_konzeptmh}](thesis-glukas-img19.png)
![\includegraphics[width=0.8\textwidth]{03_struktogramm}](thesis-glukas-img21.png)
![\includegraphics[width=0.8\textwidth]{03_wmpacket}](thesis-glukas-img25.png)